[AI 이론] 딥러닝 - 이미지 처리 이론과 실습 (Ft. MNIST)
- AI & Data/이론
- 2022. 11. 16.

딥러닝 활용
딥러닝을 활용한 분야는 크게 3가지로 나뉩니다.
이번에는 어떻게 이미지를 처리하는지 알아보겠습니다.
- ✅ 이미지 분야: 얼굴인식, 화질 개선 등
- 음성 분야: AI 스피커, 노래 인식 등
- Text 분야: 리뷰 분석, 챗봇 등
이미지 처리
이미지 인식
컴퓨터는 어떻게 이미지를 인식하는 걸까요?
컴퓨터에게 이미지는 수많은 Pixel(픽셀) 값들이 모여있는 배열입니다.
숫자인지, 사람인지, 동물인지는 당연히 모르죠.
그럼 Pixel은 뭘까요?
Pixel은 Picture Element의 합성어입니다.
Pixel은 위치별로 색상에 해당하는 값을 가진 정사각형 타일로 이해하시면 됩니다.
해상도를 말할 때도 Pixel이 기본이 되죠.
HD, FHD를 말할 때 (1280x720) 같은 숫자들이 Pixel의 수입니다.

위 그림은 MNIST Data 중 하나입니다.
오른쪽 그림을 보면 수많은 숫자들이 위치마다 나타나 있네요.
이미지는 컴퓨터에게 저렇게 숫자 배열로 인식됩니다.
이미지 데이터 전 처리
이미지 데이터도 전 처리가 필요합니다.
가장 중요한 점은 이미지 데이터들의 통일입니다.
무슨 말이냐고요? 🤔
- 해상도 통일
- HD, FHD 등 해상도 별로 Pixel의 수가 다르죠.
- Pixel의 수가 다르다는 말은 Input으로 사용될 Data 배열의 크기가 다르다는 뜻입니다.
- 색 표현 방식 통일
- 색을 표현할 수 있는 방식이 많습니다. (RGB, HSV, Gray-scale 등)
- 색의 표현 방식이 다른 Data를 사용하면 컴퓨터는 Data를 잘못 해석하게 됩니다.

위 데이터는 MNIST Data입니다.
이미지 처리를 할 때 가장 기본적으로 다루는 Data입니다. (숫자뿐만 아니라, 패션, 영어, 일어 등도 있습니다.)
MNIST Data 모두 통일이 되어 있어서 다루기 편하죠.
해상도는 (28x28)이며, 색은 Gray-scale로 표현합니다.
여기서 주의할 점은 MNIST Data를 기반으로 Model이 학습했다면
판별할 새로운 이미지의 "해상도와 색 표현 방식"을 MNIST와 동일하게 변환해야 한다는 점입니다.
이제 직접 다뤄볼 시간입니다.
이번에도 Tensorflow와 keras를 활용했습니다.
# warning 무시
import logging, os
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# 난수 고정
np.random.seed(123)
tf.random.set_seed(123)
# mnist data를 담을 그릇 생성
mnist = tf.keras.datasets.mnist
# mnist data load
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# train, test data slicing
train_images, train_labels = train_images[:5000], train_labels[:5000]
test_images, test_labels = test_images[:1000], test_labels[:1000]
print("Original Train Image data shape: ",train_images.shape)
print("Original Test Image data shape: ",test_images.shape)
print("Original Train Label data: ",train_labels)
'''
Original Train Image data shape: (5000, 28, 28)
Original Test Image data shape: (1000, 28, 28)
Original Train Label data: [5 0 4 ... 2 1 2]
'''위처럼 keras를 통해 MNIST Data를 정의한 후 "load_data()"를 해주면 Data를 다운로드하여 저장해줍니다.
이미 (train, test), (feature, label)로 나눠서 Tensor 형태로 저장되어 있어요.
그래서 다른 전 처리는 필요 없어요.😁
Split 한 후 Data를 확인해보니 3차원입니다.
이미지 Data의 수와 Pixel의 수네요.
이미지를 하나 불러서 확인해보죠.
plt.figure(figsize=(3,3)) # figure 크기
plt.imshow(train_images[0], cmap=plt.cm.binary) # 표현할 data, 색표현 방식
plt.colorbar() # 오른쪽의 Colorbar 생성
plt.title("Training Data Sample") # Title 설정
plt.savefig("sample1.png") # png 파일로 저장
plt.figure(figsize=(3,3))
plt.imshow(train_images[0], cmap=plt.cm.gray)
plt.colorbar()
plt.title("Training Data Sample")
plt.savefig("sample2.png")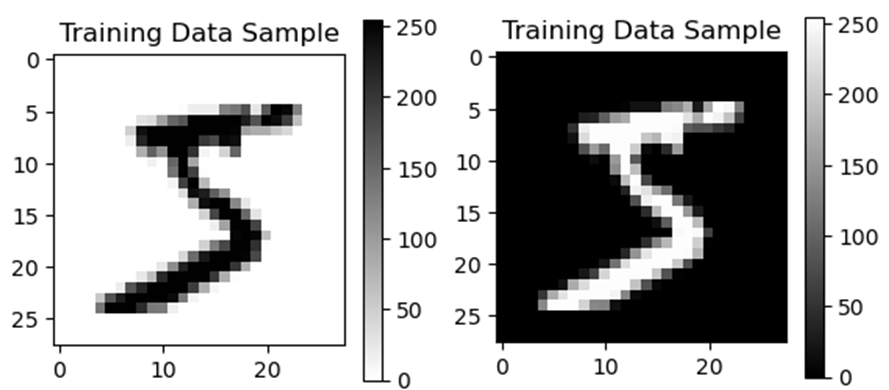
"savefig"함수로 저장도 할 수 있군요.
연습할 겸 이미지를 보여주는 함수의 옵션 중 "cmap"를 다르게 설정했습니다.
출력이 다르게 나오는 것을 확인할 수 있네요.
이제 9개의 Data를 한 번에 확인해볼게요.
# Class name 정의
class_name = ['zero', 'one', 'two', 'three', 'four',
'five', 'six', 'seven', 'eight', 'nine']
# 9개의 학습 data를 출력
for i in range(9):
plt.subplot(3,3,i+1) # 총 9개의 subplot
plt.xticks([]) # x축 tick 제거
plt.yticks([]) # y축 tick 제거
plt.grid(False) # grid 제거
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_name[train_labels[i]])
plt.savefig("sample3.png")
마지막 전 처리에서는 Data의 차원을 확장해볼게요.
Tensorflow의 "expand_dims()"라는 내장 함수를 사용하겠습니다.
# CNN Model의 입력으로 사용하기 위해 (Data 수, 가로 Pixel, 세로 Pixel, 1)의 형태로 변환
train_images = tf.expand_dims(train_images, -1)
test_images = tf.expand_dims(test_images, -1)
print("Expended Train Image data shape: ",train_images.shape)
print("Expended Test Image data shape: ",test_images.shape)
'''
Expended Train Image data shape: (5000, 28, 28, 1)
Expended Test Image data shape: (1000, 28, 28, 1)
'''
# CNN Model의 입력으로 사용하기 위해 (Data 수, 가로 Pixel, 세로 Pixel, 1)의 형태로 변환
train_images = tf.expand_dims(train_images, 1)
test_images = tf.expand_dims(test_images, 1)
print("Expended Train Image data shape: ",train_images.shape)
print("Expended Test Image data shape: ",test_images.shape)
'''
Expended Train Image data shape: (5000, 1, 28, 28)
Expended Test Image data shape: (1000, 1, 28, 28)
'''결과를 보기 전에 "expand_dims()"의 매개변수를 확인해볼게요.
확장할 Tensor가 입력으로 들어가네요.
다음에 보이는 '-1'은 "axis"라는 옵션의 값인데요. 확장할 차원이 들어갈 Index로 이해하시면 됩니다.
(두 결과값을 비교하면 이해가 되시죠?)
이미지 처리 방식
데이터 전 처리까지 진행했으니 다음은 모델의 구조와 학습시키는 방법을 알아보죠.
MLP기반 신경망
기존에 학습한 MLP기반의 신경망은 어떻게 이미지를 처리할까요?

강아지 사진으로 설명하겠습니다. 😍
임의로 (5x5)의 사진이라고 가정할게요.
[[123, 135, 213, 56, 45]
[12, 35, 123, 156, 245]
[23, 13, 21, 222, 145]
[13, 235, 173, 116, 45]
[167, 15, 93, 196, 185]]
왼쪽의 사진은 위와 같은 Pixel들의 2차원 배열입니다. (실제 값은 아닙니다.)
[123, 135, 213, 56, 45, 12, 35, 123, 156, 245, 23, 13, 21, 222, 145, 13, 235, 173, 116, 45, 167, 15, 93, 196, 185]
MLP에서는 2차원 배열을 직접 사용하지는 못해요. 1차원으로 변환해줘야 하죠.
그럼 위에 보이는 배열처럼 한 줄로 붙게 됩니다. 이후에 학습을 진행합니다.
이러한 방식에는 몇 가지 단점이 있습니다. 😥
- 많은 Parameter 필요
- pixel 수에 비례한 수많은 파라미터 필요하다는 점입니다.
- 특징 확인의 어려움
- 1차원 행렬로 변환하는 방식에 의해 특징을 확인하기 어렵습니다. 혼합이 되는 거죠.
- 강아지 귀 옆에 강아지의 엉덩이 부분의 이미지가 붙어있는 형태가 됩니다.
- 성능의 아쉬움
- 특징 확인이 어려워 이미지를 뒤집으면 다른 data로 인식할 확률이 높습니다.
- 첫 이미지는 잔디로 시작했지만, 뒤집은 이미지는 강아지의 발이 보이기 때문이죠.
- 1차원 행렬로 변환하는 방식에 의해 특징을 확인하기 어렵습니다. 혼합이 되는 거죠.
CNN (Convolution Neural Network)

기존의 MLP의 단점을 해결하는 방법으로 CNN(합성곱 신경망)이 사용됩니다.
CNN은 작은 필터를 순환시키는 방식입니다.
이를 통해 이미지의 패턴이 아닌 특징을 중점으로 인식할 수 있게 되죠.
"귀 + 코 + 다리 = 강아지"처럼 특징을 단위로 Data를 판단합니다.
이미지를 뒤집어서 특징은 유지되기 때문에 성능이 훨씬 좋아집니다.
이론적으로 접근해보겠습니다.
Convolution이란 뭘까요?
"하나의 함수와 또 다른 함수를 반전 이동한 값을 곱하고, 구간에 대해 적분하여 새로운 함수를 구하는 수학 연산자"
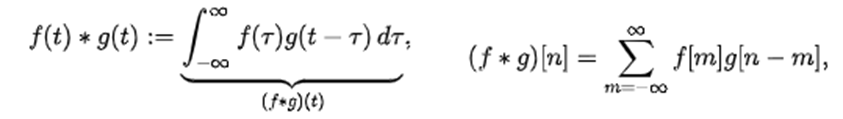
식과 설명만 봐서는 느낌이 안 오시죠?
아래 그림을 보면 확실히 이해가 되실 겁니다.

다시 CNN으로 돌아와서 이미지에 적용해보겠습니다.
이미지와 같은 2D에는 아래 그림처럼 적용됩니다. (CNN의 핵심이기 때문에 잘 보시길 바랍니다.)
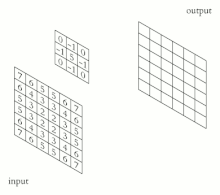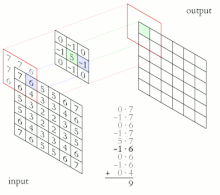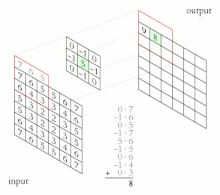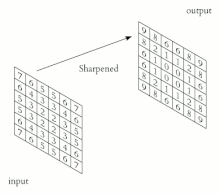
여기서 2차원의 Convolution을 진행하는 것이 Filter(Kernel)입니다.
보시는 것처럼 2차원의 각 축방향으로 Filter(Kernel)이 Sliding(이동)하면서 연산을 하죠.
이를 통해 얻어지는 결과값을 Feature map (Activation map)이라고 부릅니다.
그럼 Feature map의 값들은 어떤 의미를 갖고 있을까요?
해당 위치의 이미지는 Filter가 나타내는 Feature를 얼마나 가지고 있는지를 수치로 표현한 값입니다.
얼마나 일치하는지를 나타내는 값인 거죠.
예를 들면 "수직선이 있는지"찾는 Filter는 각 위치별로 수직선의 성분이 얼마나 있는지를 표현하는 거죠.
(참고로 Filter는 학습을 통해서 얻어집니다.)
이렇게 Convolution Filter를 통해 Feature map을 얻는 Layer를 Convolutional Layer라고 합니다.
이러한 Layer를 사용하는 인공신경망을 CNN이라 하는 거죠.
조금만 더 들여다보죠.
RGB 이미지는 (Height, Width, Channels)으로 3차원 데이터가 됩니다. (흑백 이미지는 (Height, Width) 2차원이죠.)
Input이 3차원이라면 Filter도 3차원이 되야겠죠?
Filter의 3번째 차원은 주로 Input의 3번째 차원과 크기를 같게 해서 (가로, 세로) 차원으로만 Sliding 합니다.
이렇게 한 번의 과정을 거치면 Feature map은 2차원으로 나옵니다.
여러 번의 과정 후 생성된 Featrue map들을 쌓아주면 최종적으로 3차원이 되는 거죠.

CNN의 핵심인 Convoltion Filter에 대한 설명이 끝났습니다.
이제 CNN의 구조를 보죠.

CNN은 크게 4가지 Part로 구성되어 있습니다. (그림은 Layer만 그렸어요. 😅)
- Convolution Layer
- Convolution Filter를 적용하는 Layer입니다.
- 귀 모양, 입모양, 발 모양의 Filter들이 각각 적용되면서 유사한 정도를 판단해요. (이해를 위한 설명입니다.)
- 특징 확인이 어려운 기존 MLP의 단점이 보완됩니다.
- Activation Function
- Activation Function(ReLU, sigmoid 등)가 적용됩니다.
- Pooling Layer
- Feature map의 크기를 줄여서 Overfitting을 억제하고 계산량을 줄여 줍니다.
- Parmeter 수가 너무 많은 기존 MLP의 단점을 보완해줍니다.
- Fully-Connected Layer (FC)
- 기존의 MLP와 같다고 생각하면 됩니다.
- Convolution, Pooling을 거친 Feature map은 MLP에 Input으로 사용됩니다.
- FC를 거친 결과값은 분류해야 할 최종 Label의 수와 같은 수가 나와야 합니다.
- 이렇게 여러 Label에 대한 값이 나오는 경우에는 Activation Function으로 Softmax를 사용합니다.
Convolution Layer ~ Pooling Layer를 반복해서 더 구체적으로 분류가 가능한 Filter를 만들어 줍니다.
(세분화된 특징들을 구별할 수 있다는 의미입니다.)

새로운 친구가 보이는군요. 🤗
"Pooling Layer"의 역할은 Feature map의 크기를 줄이는 것입니다. (노이즈와 왜곡을 줄여줄 수도 있습니다.)
이로 인해 MLP의 단점인 Parameter 수가 많아서 발생하는 문제가 보완됩니다.
Pooling Layer은 새로운 Data를 만들지 않아요. 물론 주어진 Data를 임의로 버리지도 않죠.
그렇다면 어떻게 Feature map의 크기를 줄이는 걸까요?
바로 Convolution Filter처럼 Pooling Filter를 사용합니다. 👍
Filter의 종류에 따라 Pooling의 방식도 구별됩니다.
- Max Pooling: 영역 내에서 가장 큰 값을 대표값으로 삼아 Feature map을 요약하는 방법입니다. (주로 사용해요.)
- Average Pooling: 영역 내의 평균을 대표값으로 삼아 Feature map을 요약하는 방법입니다.
그리고 Pooling Layer에서 사용하는 용어(기법)도 새로 나옵니다.
- Padding: Input의 가장자리에 추가적인 값('0')을 넣어서 손실되는 정도를 줄여 줍니다.
- Striding: Filter를 Sliding 하는 간격을 의미합니다. (Convolution Filter에서도 사용 가능합니다.)
Pooling Layer를 통과해서 변한 Feature map의 크기는 아래 공식으로 구할 수 있습니다.
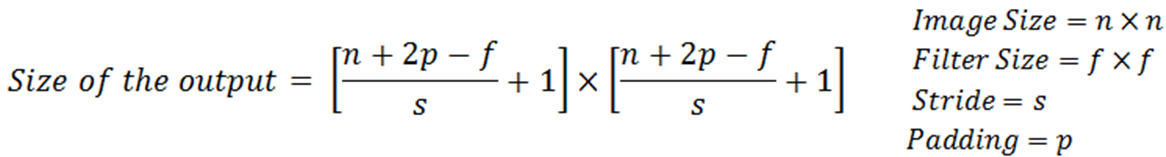
여기까지가 CNN의 구조와 학습 원리에 대한 설명이었습니다. (정말 길었네요. 😨)
코딩을 해보기 전에 실제 CNN에 가까운 구조를 보고 갈까요?

Convolution, Activation, Pooling이 적용되는 위치를 보다 잘 이해할 수 있겠네요. 🎉
CNN을 활용해 "Object detection, Segmentation, Super resolution"과 같은 기능을 수행하는 모델을 만들 수 있습니다.
드디어 실전에 적용할 시간입니다.
이미지 데이터 전 처리과정에 이어서 코딩할 건데요. 앞서 설명한 라인은 넘어가겠습니다.
# warning 무시
import logging, os
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# 난수 고정
np.random.seed(123)
tf.random.set_seed(123)
# mnist data를 담을 그릇 생성
mnist = tf.keras.datasets.mnist
# mnist data load
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# train, test data slicing
train_images, train_labels = train_images[:5000], train_labels[:5000]
test_images, test_labels = test_images[:1000], test_labels[:1000]
# CNN Model의 입력으로 사용하기 위해 (Data 수, 가로 Pixel, 세로 Pixel, 1)의 형태로 변환
train_images = tf.expand_dims(train_images, -1)
test_images = tf.expand_dims(test_images, -1)
# CNN 모델 만들기
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32, kernel_size=(3,3), activation='relu', padding='SAME', input_shape=(28,28,1)),
tf.keras.layers.MaxPool2D(padding='SAME'),
tf.keras.layers.Conv2D(filters=32, kernel_size=(3,3), activation='relu', padding='SAME'),
tf.keras.layers.MaxPool2D(padding='SAME'),
tf.keras.layers.Conv2D(filters=32, kernel_size=(3,3), activation='relu', padding='SAME'),
tf.keras.layers.MaxPool2D(padding='SAME'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
print(model.summary())
모델의 구성을 보면 앞서 설명한 것처럼 MLP 앞에 Convolution Layer와 Pooling Layer가 위치해있습니다.
그리고 각 Layer들에 맞는 Activation Function들이 사용되고 있네요.
함수를 하나씩 살펴볼게요.
먼저 Convolution Layer를 만드는 함수입니다.
"tf.keras.layers.Conv2D(filters=, kernel_size=, actiavtion=, padding=, input_shape=())"
다음 함수는 Pooling Layer를 구성하는 함수입니다. (max pooling을 했네요.)
"tf.keras.layers.MaxPool2D(padding='')"
인자들의 의미를 살펴보죠.
- filters: Filter(kernel)의 수
- kernel_size: Filter(kernel)의 크기
- activation: Activation Function 설정
- padding: Padding 여부 설정
- VALID: no padding
- SAME: do padding
- input_shape: Input shape 전달
- 첫 Layer에서는 Input의 shape를 알려줘야 합니다.
- ⚠️주의⚠️ Convolution에서 input_dim은 사용할 수 없습니다.
여기까지 거치면 Convolution Layer와 Pooling Layer를 지난 겁니다.
결과로는 Feature map (N차원 Tensor 형태)이 나와있겠네요.
"tf.keras.layers.Flatten()"
이번 함수는 FC Layer에서 사용할 수 있게 Feature map을 1차원으로 바꿔주는 함수입니다.
"tf.keras.layers.Dense(node 수, activation='')"
그리고 나오는 함수는 이전 글 "(딥러닝 모델의 학습방법(링크))"에서 소개한 MLP를 구성하는 함수입니다.
[AI 이론] 딥러닝 모델의 학습 방법과 개념 (Ft. Tensorflow, Keras)
딥러닝 모델이란? 딥러닝 모델에 대해서는 "퍼셉트론 한방에 끝내기(링크)"에서 소개한 적이 있죠? 다시 한번 보고 가겠습니다. 딥러닝 "딥러닝" 딥러닝은 머신러닝의 하위 개념입니다. 머신러닝
kay-dev.tistory.com
지금 사용하고 있는 Data는 MNIST입니다.
총 10개의 Label이 있으니까 마지막 node는 10개가 되어야 합니다.
이번에는 학습 방법 설정 및 학습 코드입니다.
첫 5 Epoch와 마지막 5 Epoch의 차이가 확실히 보이네요.
이제 CNN 모델의 학습 방법에 대해 설정하겠습니다.
# CNN 모델의 학습 방법 설정
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 학습 진행
history = model.fit(train_images, train_labels, epochs=20, batch_size=512)

이번 모델의 최종 목표는 다중분류이기 때문에 Loss function으로 "spars_categorical_crossentropy"를 사용했네요.
"metrics"라는 새로운 인자도 보입니다.
"metircs"는 평가의 기준을 의미합니다.
학습에는 영향을 미치지 않지만 학습 과정이 잘 수행되고 있는지를 중간 중간 확인할 수 있죠.
지금은 'accuracy'를 출력하도록 했지만, 사용자가 직접 정의할 수도 있습니다.
이번엔 시각화 부분입니다.
위에서 숫자로 표기한 Loss를 Graph로 표현하는 코드입니다.
직접 함수를 정의하고 실행했습니다.
확실히 시각화를 잘하면 정보를 이해하는데 큰 도움이 되네요.
# Loss graph를 위한 함수 정의
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.utils import to_categorical
def Visualize(histories, key='loss'):
for name, history in histories:
plt.plot(history.epoch, history.history[key],
label=name.title()+' Train')
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0, max(history.epoch)])
plt.savefig("plot.png")
# Graph 출력
Visualize([('CNN', history)], 'loss')
모델이 학습을 했으니 다음은 평가와 예측을 해야겠죠?
총 3개의 Part로 구성했습니다. (평가, 예측, 결과 출력)
# 모델 평가
loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
# 평가용 Data에 대한 예측 결과를 저장
y_prob = model.predict(test_images)
predicted = y_prob.argmax(axis=-1) # muti classes
#predicted = (model.predict(test_images) > 0.5).astype("int32") # single classes
## 주의 predict_classes 는 tensorflow 2.6 이후로 삭제
# 평가 및 예측결과 출력
print('Test Loss: {:.4f} | Test Accuracy: {}'.format(loss, test_acc))
print('Predicted Test Data Class: ',predicted[:10])
'''
Test Loss: 0.2494 | Test Accuracy: 0.9240000247955322
Predicted Test Data Class: [7 2 1 0 4 1 4 9 5 9]
'''모델의 평가 역시 바로 "이전 글(링크)"에서 다뤘으므로 설명은 생략할게요.
[AI 이론] 딥러닝 모델의 학습 방법과 개념 (Ft. Tensorflow, Keras)
딥러닝 모델이란? 딥러닝 모델에 대해서는 "퍼셉트론 한방에 끝내기(링크)"에서 소개한 적이 있죠? 다시 한번 보고 가겠습니다. 딥러닝 "딥러닝" 딥러닝은 머신러닝의 하위 개념입니다. 머신러닝
kay-dev.tistory.com
예측 결과 부분에서 ⚠️주의⚠️할 점이 있습니다. (편리한 함수가 없어졌어요.😥)
"predict_classes()"라는 내장 함수는 Tensorflow 2.6 이후로 삭제되어 위 코드와 같이 실행해야 합니다.
어떤 과정인지 설명해드릴게요.
한 번의"predict()"의 결과마다 총 10개의 예측값들(확률)이 저장되겠죠.
이 중 어떤 예측값이 가장 큰지. 즉, 모델이 어떤 값으로 예측했는지를 확인하는 작업을 따로 해줘야 합니다.
그 부분은 "argmax()"라는 함수를 통해서 진행한 거죠. ("Activation Function을 다룬 글(링크)"에서 본 적이 있습니다.)
출력한 결과를 보니 학습의 마지막보다는 Loss가 크지만 92%는 넘는 정확도를 보이고 있네요.
그리고 Class로도 출력이 되는 것을 확인할 수 있습니다.
[AI 이론] 활성 함수 한방에 끝내기 (Activation Function)
Activation Function (활성 함수) Activation Function의 역할 한마디로 말하면 모델의 선형성을 없애주는 역할입니다. 이전 글 "퍼셉트론 한방에 끝내기(링크)"에서 SLP, MLP에 대해 알아봤죠? SLP를 선형 분류
kay-dev.tistory.com

위 그림은 따로 정의한 함수로 출력한 결과인데요.
위에서부터 아래로 갈수록 "CNN을 지나는 과정을 시각화한 것"이라고 생각하시면 됩니다.
한 Layer에 여러 개의 Data가 보이는 것은 여러 Filter들을 적용한 결과라고 보시면 됩니다.
그리고 Maxpooling을 진행할수록 Size가 줄어드는 것도 확인할 수 있네요.
여기까지 "딥러닝 - 이미지 처리 방법"에 대해 알아봤어요.
다음 글로는 "자연어 처리"에 대해 알아볼 계획입니다.
글이 도움이 되셨다면 공감 버튼 눌러주세요. 😊
'AI & Data > 이론' 카테고리의 다른 글
| [AI 이론] 딥러닝 - 자연어(Text) 처리 이론과 실습 (Ft.RNN) (0) | 2022.11.17 |
|---|---|
| [AI 이론] 딥러닝 모델의 학습 방법과 개념 (Ft. Tensorflow, Keras) (0) | 2022.11.14 |
| [AI 이론] 손실 함수 한방에 끝내기 (Loss Function) (0) | 2022.11.11 |
| [AI 이론] 활성 함수 한방에 끝내기 (Activation Function) (0) | 2022.11.10 |
| [AI 이론] 딥러닝 - 퍼셉트론 한방에 끝내기 (Perceptron) (0) | 2022.11.08 |