[AI 이론] 활성 함수 한방에 끝내기 (Activation Function)
- AI & Data/이론
- 2022. 11. 10.
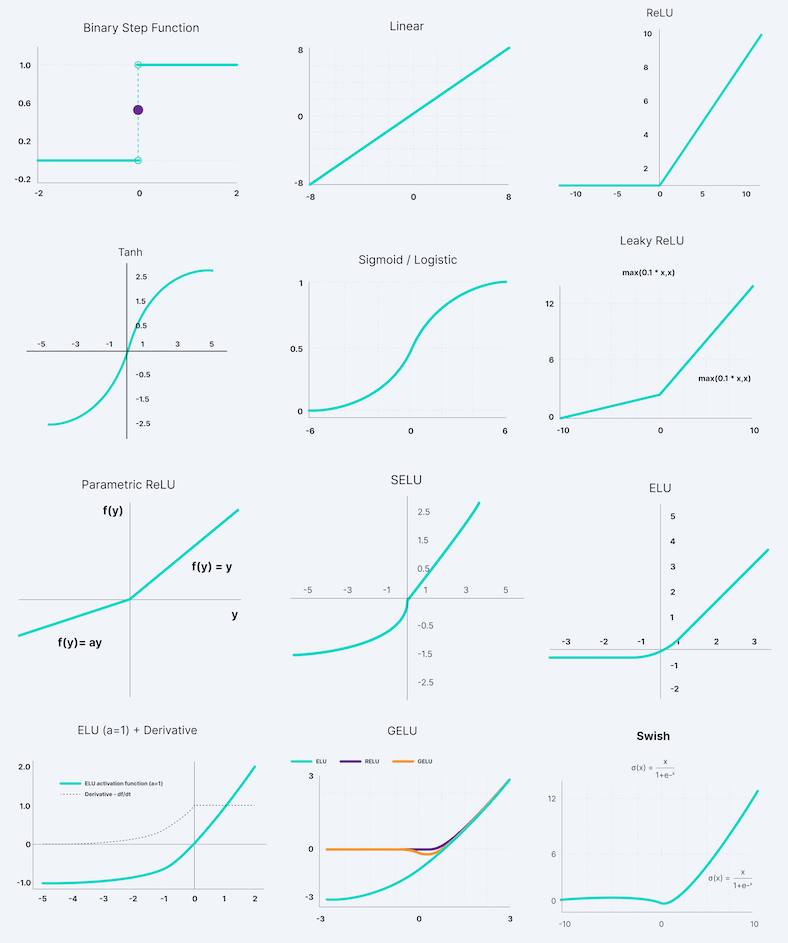
Activation Function (활성 함수)
Activation Function의 역할
한마디로 말하면 모델의 선형성을 없애주는 역할입니다.
이전 글 "퍼셉트론 한방에 끝내기(링크)"에서 SLP, MLP에 대해 알아봤죠?
[AI 이론] 딥러닝 - 퍼셉트론 한방에 끝내기 (Perceptron)
딥러닝 왜 사람들은 딥러닝을 이야기할 때 "뇌" 이미지를 자주 사용합니다. AI가 사람처럼 생각을 하는 걸까요? 곧 가능하겠지만, 아직은 아닌 것 같습니다. 왜 "뇌" 이미지가 등장하는지 AI에 대
kay-dev.tistory.com
SLP를 선형 분류기로 표현하면서 Input 간의 관계를 찾을 수 없다는 얘기를 했어요.
조금 더 생각해보죠.
각 Layer의 Input과 Weight는 Vector입니다. 연산은 행렬 곱이라는 뜻이죠. 당연히 결과는 행렬입니다.
Input과 Weight의 연산만 수행하는 Layer들을 겹쳐주면 MLP가 될까요? 🤔
물론 아닙니다.
여러 행렬들이 곱해지지만 결과는 이미 알고 있던 행렬이고 선형성은 유지됩니다. 결국 SLP인 거죠.

식으로 보면 이해가 빠를 겁니다.
W행렬들과 U들을 여러 번 곱하면 결국 하나의 W행렬과 X행렬의 곱인 거죠.
SLP로도 표현이 가능한 선형 모델인 Linear Classification, Linear Regression이라는 뜻입니다. (MLP)
(이 경우는 심지어 입력에 이상치가 들어있을 때 정제하지 못하는 상황도 나옵니다.)
이때 필요한 것이 Activation Function입니다.
그런데 어떻게 선형성을 없앨까요?

각 Layer 별로 선형 결합 후 다음 Layer로 넘어가기 전에 비선형 성질을 가진 Activation Function을 적용합니다.
그럼 위 식처럼 결과가 달라집니다. (a: activation function)
모델이 다양한 표현력을 갖게 된 거죠.🎉
Actication Function의 종류
사실 비선형 성질이 있는 함수라면 모두 Activation Function으로 사용할 수는 있습니다.
그렇지만 딥러닝 모델의 학습에 유용한 특징들이 있는 함수가 주로 사용되죠.
어떤 특징들일까요?
- 연산이 빠른 함수
- 학습을 위한 미분계수의 계산이 빠른 함수
- 데이터가 분포한 범위에 맞는 함수
Activation Function은 MLP를 Forward Propagataion 하는데 주로 사용됩니다.
학습을 위해 Back Propagation에도 사용되어 Activation Function의 미분계수를 계산하는 과정도 있습니다.
그리고 Activation Function과 데이터의 범위가 맞지 않으면 그 결과는 Linear 한 모델이 되는 경우도 있죠.
그럼 대표적으로 사용하는 Sigmoid, tanh, ReLU, Leaky ReLU, Softmax에 대해 소개할게요.
1️⃣ Sigmoid Function
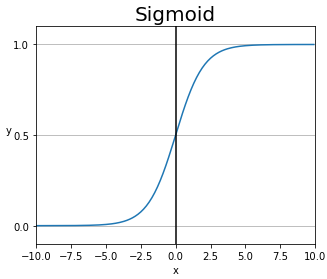


첫 번째 Actication Function은 Sigmoid Function입니다.
전통적으로 많이 사용되던 함수죠. 주로 Output Layer에서 많이 사용했습니다.
Sigmoid Function의 특징은 아래와 같습니다.
- Step Function이 부드럽게 연결된 형태입니다.
- 입력 값이 들어오면 0 ~ 1 사이의 값을 Return 합니다.
- 이진 분류에 활용됩니다. (Ex, 성별 구분)
- 출력의 중앙값이 0.5이며, 모든 값이 양수이기 때문에 Bias Gradient가 발생한다.
- Bias Gradient: Outpt의 weight 합 > Input의 Weight 합
- 최종적으로 0, 1에 수렴하게 된다.
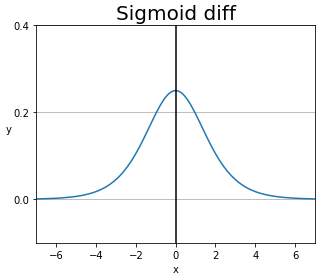
- 미분계수의 계산이 간편해 Back Propagation에 유용합니다.
- Sigmoid Function을 미분한 결과는 본래 함수를 이용해 표현할 수 있습니다.
- 하지만 미분 계수의 값이 0이 되는 영역이 너무 넓어서 발생하는 단점도 있습니다. (Vanishing Gradient)
미분 그래프를 보면 입력이 5만 넘더라도 미분 계수는 사실상 '0'이 됩니다.

그렇다면 Vanishing Gradient는 뭐고, 왜 단점이 되는 걸까요?
Vanishing Gradient는 미분 함수에 대해 Input 값이 일정 이상으로 커지면 미분 값이 소실되는 현상입니다.
이해를 위해 MLP를 잠깐 보고 갈게요.
MLP의 Output과 Loss Function을 통해 MLP가 얼마나 잘 작동하고 있는지 표현할 수 있는데요.
이때 Loss의 편미분 값을 이용해 각 Layer의 Parmeter를 Update 해 MLP의 성능을 높입니다.
이게 딥러닝 모델의 Back Propagation이라는 학습 알고리즘입니다.
MLP는 여러 Layer들이 쌓인 형태이고, Back Propagation 연산 과정에서 미분 값들이 곱해지는데요.
Vanishing Gradient(기울기 소실)은 이런 과정이 진행되면서 점점 Gradient가 소실되는 현상입니다.
Activation Function의 미분이 0이 되는 구간이 넓기 때문이죠.
결과적으로는 MLP의 학습이 잘 되지 않게 됩니다.
이를 보완하기 위해 등장한 게 ReLU Function입니다.
아래에서 살펴볼게요.
다음으로 넘어가기 전에 직접 Sigmoid Function을 구현해볼게요.
출력 결과는 Sigmoid Function 설명의 위쪽의 두 그래프입니다.
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x, diff=False): # default: False
if diff:
return sigmoid(x) * (1 - sigmoid(x)) # sigmoid diff
else:
return 1 / (1 + np.exp(-x)) # sigmoid
# sigmoid
x = np.arange(-10.0, 10.0, 0.1)
y = sigmoid(x)
fig = plt.figure(figsize=(5,4))
fig.set_facecolor('white')
plt.plot(x, y)
plt.xlim(-10, 10)
plt.ylim(-0.1, 1.1)
plt.title("Sigmoid", fontsize=20)
plt.xlabel("x", fontsize=10)
plt.ylabel("y", rotation=0, fontsize=10)
plt.yticks([0.0, 0.5, 1.0])
plt.axvline(0.0, color='k')
ax = plt.gca()
ax.yaxis.grid(True)
plt.show()
# sigmoid diff
y_diff = sigmoid(x, True)
fig = plt.figure(figsize=(5,4))
fig.set_facecolor('white')
plt.plot(x, y_diff)
plt.xlim(-7, 7)
plt.ylim(-0.1, 0.4)
plt.title("Sigmoid diff", fontsize=20)
plt.xlabel("x", fontsize=10)
plt.ylabel("y", rotation=0, fontsize=10)
plt.yticks([0.0, 0.2, 0.4])
plt.axvline(0.0, color='k')
ax = plt.gca()
ax.yaxis.grid(True)
plt.show()2️⃣ tanh Function




tanh Function은 Sigmoid Function과 굉장히 비슷한 형태입니다.
Sigmoid Function의 단점을 일부 보완했지만, 완전히 해결하지는 못했습니다.
tanh Function은 중앙값이 0 이기 때문에 Bias Gradient가 발생하지 않아요.
이로 인해 Sigmoid Function에 비해 학습 효율이 좋죠.
Vanishing Gradient 현상은 Sigmoid Function에 비해 적지만 여전히 존재합니다.
다음으로 넘어가기 전에 직접 tanh Function을 구현해볼게요.
출력 결과는 tanh Function 설명의 위쪽의 두 그래프입니다.
그리고 Sigmoid와 tanh의 미분 함수 그래프도 비교했으니 참고하세요.
import numpy as np
import matplotlib.pyplot as plt
def tanh(x, diff=False):
if diff:
return (1 + tanh(x)) * (1 - tanh(x))
else:
return np.tanh(x)
# tanh
x = np.arange(-5.0, 5.0, 0.1)
y = tanh(x)
fig = plt.figure(figsize=(5,4))
fig.set_facecolor('white')
plt.plot(x, y)
plt.xlim(-5, 5)
plt.ylim(-1.1, 1.1)
plt.title("tanh", fontsize=20)
plt.xlabel("x", fontsize=10)
plt.ylabel("y", rotation=0, fontsize=10)
plt.yticks([-1.0, 0.0, 1.0])
plt.axvline(0.0, color='k')
ax = plt.gca()
ax.yaxis.grid(True)
plt.show()
# tanh_diff
y_diff = tanh(x, True)
fig = plt.figure(figsize=(5,4))
fig.set_facecolor('white')
plt.plot(x, y_diff)
plt.xlim(-5, 5)
plt.ylim(-1.1, 1.1)
plt.title("tanh diff", fontsize=20)
plt.xlabel("x", fontsize=10)
plt.ylabel("y", rotation=0, fontsize=10)
plt.yticks([-1.0, 0.0, 1.0])
plt.axvline(0.0, color='k')
ax = plt.gca()
ax.yaxis.grid(True)
plt.show()
# sig_diff & tanh_diff
x = np.arange(-10.0, 10.0, 0.1)
y_sig_diff = sigmoid(x, True)
y_tanh_diff = tanh(x, True)
fig = plt.figure(figsize=(5,4))
plt.plot(x, y_sig_diff, c='blue', linestyle="--", label = "sigmoid_diff")
plt.plot(x, y_tanh_diff, c='red', label = "tanh_diff")
plt.xlim(-6.5, 6.5)
plt.ylim(-0.5, 1.2)
plt.title("Sigmoid_diff & tanh_diff", fontsize=20)
plt.xlabel("x", fontsize=10)
plt.ylabel("y", rotation=0, fontsize=10)
plt.legend(loc='upper right')
plt.axvline(0.0, color='k')
ax = plt.gca()
ax.yaxis.grid(True)
ax.xaxis.grid(True)
plt.show()3️⃣ ReLU Function (Rectified Linear Unit)
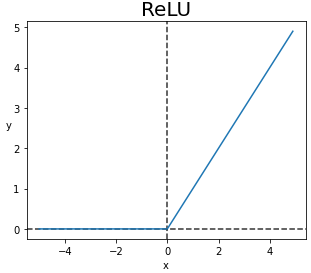

ReLU Function은 Hidden Layer에서 가장 많이 사용하는 Activation Function입니다.
왜 Hidden Layer에서 많이 사용할까요?
먼저 Sigmoid Function에서 발생한 Vanishing Gradient 문제를 해결했습니다.
Input이 '0'보다 크기만 하면 'Gradient=1' 이기 때문에 양수이기만 하면 학습을 진행해도 사라지지 않는 것이죠.
또한 ReLU Function은 미분도 계산이 빠릅니다.
덕분에 Forward, Backward 모두에 효율이 좋습니다.
물론 ReLU Function에도 한계는 있습니다.
음수의 Input에서 모두 0을 반환하는 점이죠.
Weight의 합이 '0'이 되는 순간 ReLU도 '0'을 반환하고 그 뉴런은 '0'만 반환하는 현상이 발생합니다.
이를 Dying ReLU 현상이라고 합니다.
중요한 Activation Function인 ReLU Fucntion을 구현해볼게요.
출력 결과는 설명 위쪽에 있는 그래프입니다.
import numpy as np
import matplotlib.pyplot as plt
def ReLU(x):
return np.maximum(0, x)
x = np.arange(-5.0, 5.0, 0.1)
y = ReLU(x)
fig = plt.figure(figsize=(5,4))
fig.set_facecolor('white')
plt.title('ReLU', fontsize=20)
plt.xlabel('x', fontsize=10)
plt.ylabel('y', rotation=0, fontsize=10)
plt.axvline(0.0, color='k', linestyle='--', alpha=0.8)
plt.axhline(0.0, color='k', linestyle='--', alpha=0.8)
plt.plot(x, y)
plt.show()4️⃣ Leaky ReLU Function
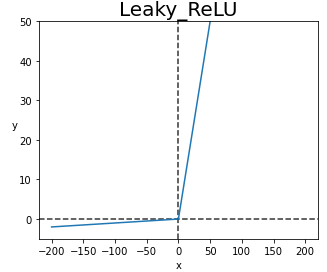

ReLU Function에서 발생한 한계도 보완해주면 좋겠죠?
이를 위해 등장한 Activation Function이 Leaky ReLU입니다.
ReLU Fucntion을 기본으로 하고, 음수에서 '0.01'을 곱해서 Dying ReLU현상을 방지했습니다.
하지만 음수에서 생긴 선형성으로 인해 복잡한 분류에서 사용할 수 없는 한계가 있습니다.
한계로 인해 성능이 좋지 않아 음수 Input을 꼭 고려할 상황에서만 사용하는 것이 좋습니다.
Leaky ReLU Function도 직접 구현해볼게요.
출력 결과는 설명 위쪽에 있는 그래프입니다.
import numpy as np
import matplotlib.pyplot as plt
def Leaky_ReLU(x):
return np.maximum(0.01*x, x)
x = np.arange(-200.0, 200.0, 0.1)
y = Leaky_ReLU(x)
fig = plt.figure(figsize=(5,4))
fig.set_facecolor('white')
plt.ylim(-5, 50)
plt.title('Leaky_ReLU', fontsize=20)
plt.xlabel('x', fontsize=10)
plt.ylabel('y', rotation=0, fontsize=10)
plt.axvline(0.0, color='k', linestyle='--', alpha=0.8)
plt.axhline(0.0, color='k', linestyle='--', alpha=0.8)
plt.plot(x, y)
plt.show()
5️⃣ Softmax Function
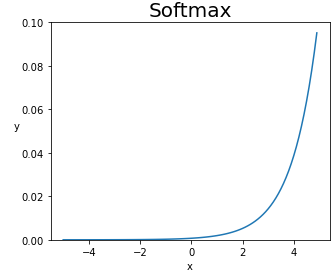

이번에 소개할 Softmax Function은 Output Layer에서 주로 사용하는 함수입니다.
Sigmoid Function이 이진 분류에 주로 사용된다면 Softmax Function은 다중 분류에 사용됩니다.
Softmax Function은 모델 Output을 확률 분포의 형태로 만들어줍니다. (총합은 '1'입니다.)
따라서 결과로 나온 값들은 확률이기 때문에 이를 Class에 속할 확률로 해석합니다.
단, 이때 Output들은 서로 연관성이 없어야 합니다. (지켜야 할 규칙이 없어야 한다는 뜻이죠)
Sigmoid Function을 구현해봐야겠죠?
출력 결과는 Sigmoid Function 설명의 위쪽의 두 그래프입니다.
import numpy as np
import matplotlib.pyplot as plt
def softmax(x):
array_x = x - np.max(x) # input - input의 최대값: Overflow 방지
exp_x = np.exp(array_x)
result = exp_x / np.sum(exp_x)
return result
x = np.arange(-5, 5, 0.1)
y = softmax(x)
fig = plt.figure(figsize=(5,4))
fig.set_facecolor('white')
plt.plot(x, y)
plt.ylim(0, 0.1)
plt.title('Softmax', fontsize=20)
plt.xlabel('x', fontsize=10)
plt.ylabel('y', rotation = 0, fontsize=10)
plt.show()6️⃣ ETC...


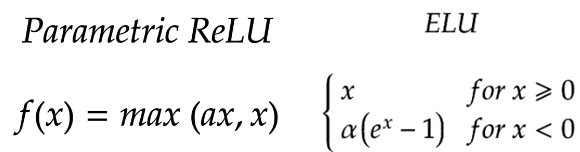
소개한 것들 외에도 여러 Activation Function들이 있습니다.
그중 ReLU의 Family들만 간단히 소개할게요.
- PReLU (Parametric ReLU)
- max에 들어갈 a를 같이 학습합니다.
- 이로 인해 각 Layer에 들어갈 Actication Function들이 조금씩 다릅니다.
- ELU (Exponential Linear Units)
- Leaky ReLU가 보다 부드러워진 형태입니다.
- 음수 부분이 Saturation 됩니다.
- 일반적으로 -1에 수렴해요.
- Saturation이기 때문에 Gradient가 '0'이 아닙니다.
지금까지 Activation Function들은 직접 구현했습니다.
하지만 실전에서는 하나씩 구현할 필요가 없어요. 😱
우리에겐 Python의 친절한 라이브러리들이 있으니까요.
Pytorch라는 라이브러리에는 오늘 소개한 Activation Function들이 모두 구현되어 있답니다. 😎
여기까지 "Activation Function"에 대해 알아봤어요.
다음에는 "Loss Function"에 대해 알아보겠습니다.
글이 도움이 되셨다면 공감 버튼 눌러주세요. 😊
'AI & Data > 이론' 카테고리의 다른 글
| [AI 이론] 딥러닝 모델의 학습 방법과 개념 (Ft. Tensorflow, Keras) (0) | 2022.11.14 |
|---|---|
| [AI 이론] 손실 함수 한방에 끝내기 (Loss Function) (0) | 2022.11.11 |
| [AI 이론] 딥러닝 - 퍼셉트론 한방에 끝내기 (Perceptron) (0) | 2022.11.08 |
| [AI Algorithm] 지도학습 - 분류 한방에 끝내기 (Classification / Ft. Decision Tree) (0) | 2022.11.08 |
| [AI Algorithm] 지도학습 - 선형 회귀 한방에 끝내기 (Linear Regression) (0) | 2022.11.03 |