
딥러닝 모델이란?
딥러닝 모델에 대해서는 "퍼셉트론 한방에 끝내기(링크)"에서 소개한 적이 있죠?
다시 한번 보고 가겠습니다.
딥러닝
"딥러닝"
딥러닝은 머신러닝의 하위 개념입니다.
머신러닝의 한 방식으로 "인공 신경망(Artificial Neural Network)"라는 알고리즘이 활용되죠.
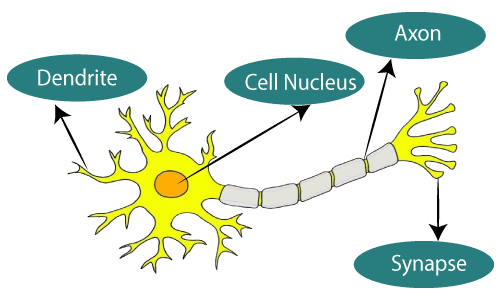

"인공 신경망"은 인간의 뇌, 특히 뉴런의 연결 구조에서 영감을 받은 학습 알고리즘입니다.
수많은 뉴런들이 연결된 것처럼 Layer들이 연결되어 있죠.
이런 Neural Network의 Layer들이 많아지면서 Deep한 Neural Network라는 의미에서
Deep Learning이라는 단어를 사용했다고 해요.
구성 요소
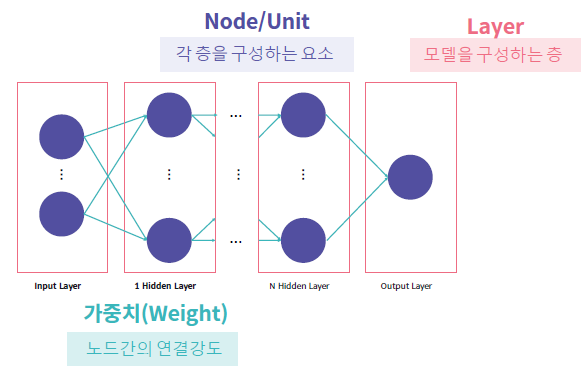
퍼셉트론에 대해 설명하면서 Weight, Layer, Node를 이미 접했습니다.
이번 글에서 확실히 정리하고 넘어가죠!
Weight를 먼저 볼까요?
Input으로 사용되는 Data들이 다음 Layer에 있는 Node에 미치는 영향력이라고 생각하시면 쉽습니다.
최종적으로는 Loss Function을 최소로 만드는 Weight를 찾는 것이 포인트죠!
다음은 Node (Unit)입니다.
각 Layer를 구성하는 요소죠.
Input과 Weight의 계산, Activation Function 적용 등을 통해 다음 Layer에 전달할 값을 만들어 냅니다.
Layer입니다.
모델을 구성하는 각 층들을 의미합니다.
많은 Layer로 구성해 Deep Learning이라고 부를 수 있게 됐다고 했죠.
이 때, Layer의 수를 셀 때는 Input Layer는 제외합니다.
(연산이 이뤄지는 Layer만 취급합니다.)
딥러닝 모델의 학습방법
모델의 학습은 예측값과 실제값 간의 오차를 최소화 하는 것이 목표입니다.
그래서 오차값을 최소화하는 모델의 인자를 찾는 알고리즘을 적용하죠.
즉, Loss Function을 최소화하는 Weight를 찾는 최적화 알고리즘을 적용한다는 뜻입니다.
딥러닝 모델의 학습 순서
- Forward Propagation (순전파)
학습용 Feature Data를 입력해 예측값을 구하는 과정입니다. - Loss 계산
예측값과 실제값의 오차를 구하고, 이를 최적화합니다. - Back Propagation (역전파)
Loss를 줄이는 Weight를 찾아서 Update 해주는 과정입니다. - 반복
1~3번 과정을 반복 진행해서 Loss를 최소로 하는 Weight를 찾아줍니다.
Forward Propagation (순전파)
순전파는 Input Layer에서 시작해 Hidden Layer들을 거쳐 Output Layer로 진행합니다.
그 결과로 모델의 예측값이 나오죠.

과정이 어떻게 진행되는지 임의의 수를 넣어서 볼게요.
"x1=1, x2=-1"의 Input과 "w1=2, w2=1"이라는 Weight로 시작합니다.
둘을 연산해주고 활성화 함수를 거쳐서 나온 값이 "0.73과 0.5"입니다.
이 값은 다음 Layer의 Input이 돼서 동일하게 계산을 진행하죠.
이런 식으로 계산을 하니 최종 예측값으로 0.436이 나오는군요.
그림의 오른쪽을 보면 "예측값은 0.436, 실제값은 0.4"임이 보이네요.
둘 사이의 오차가 우리가 줄여야 할 Loss입니다.
어떻게 줄이면 될까요?
Gradient descent (경사 하강법)
Loss를 최적화(Optimization)하는 방법 중 하나가 Gradient descent입니다.
"선형 회귀 한방에 끝내기(링크)"에서 산을 내려가는 것에 비유하면서 소개했었죠.
[AI Algorithm] 지도학습 - 선형 회귀 한방에 끝내기 (Linear Regression)
회귀 (Regression) 회귀 분석이란? 둘 이상의 변수가 있을 때 이들 간의 관계를 보여주는 통계적인 방법입니다. 나아가서 데이터를 가장 잘 설명하는 모델을 찾아 입력값에 따른 미래 결과값을 예측
kay-dev.tistory.com
이 과정에서 최소값을 찾기 위해 미분이 활용됩니다.
(자세한 내용은 글이 길어지니 따로 다루겠습니다.)
Gradient descent는 각 가중치마다 정해지고 Back Propagation의 과정으로 구합니다.
이렇게 구한 Gradient descent를 Weight에 반영해 Update 해줍니다.


Back Propagation (역전파)

Back Propagation은 이름에서 느껴지듯이 Forward Propagation의 반대 방향으로 진행합니다.
각 Weight가 출력에 미친 영향도를 구하는데요. 이 값을 Gradient로 활용합니다.
딥러닝 모델 구현하기
모델을 구현하는 순서는 아래와 같습니다.
설명도 아래 순서대로 진행하겠습니다.
- 데이터 전 처리
- 딥러닝 모델 구축
- 모델 학습
- 평가 및 예측
Tensorflow

설명에 앞서 중요한 라이브러리를 잠시 소개할게요.
Tensorflow는 데이터 그래프를 수치적으로 연산하기 위해 구글에서 만든 Open-Source Library입니다.
C++을 기본으로 구현되어 있으며, Python, Java, Go 등 다양한 언어를 지원합니다.
그중 Python를 최우선으로 지원하며 라이브러리로 제공됩니다.
Tensorflow 기반 딥러닝 모델은 Tensor 형태의 Data를 입력으로 받습니다.
여기서 Tensor란 행렬로 표현할 수 있는 2차원 배열을 높을 차원으로 확장한 다차원 배열입니다.
(다차원 배열을 담고 있는 Node와 이를 다양한 연산으로 연결하고 있는 Edge로 구성되어 있습니다.)
그리고 이런 Tensor들이 서로 연산을 통해 값을 주고받는 Flow(흐름)으로 동작합니다.
데이터 전 처리
이제 데이터 전처리를 해볼까요?
Data 형태 변환

앞서 설명한 Tensorflow를 사용하기 위해서 Data를 Tensor 형태로 변환해주어야 합니다.
Data를 "Numpy array"나 "Pandas DataFrame"으로 바꾼 것처럼 말이죠.
Epoch & Batch

딥러닝에 필요한 데이터 전 처리는 아직 끝나지 않았습니다.
여기서 Epoch와 Batch라는 개념이 등장합니다.
1 Epoch는 전체 Data Set에 대해 한 번의 학습을 진행한 상태를 의미합니다. (몇 Epoch를 진행할지는 설정하기 나름!)
Batch는 하나의 Data Set을 여러 개로 나웠을 때의 단위입니다.
딥러닝 모델의 학습에는 Data Set을 한 번에 넣지 않고 나눠서 넣죠! (Batch Size도 정하기 나름!!)
일반적으로 mini-batch라고도 합니다.
그리고 interation은 Epoch를 나누어 실행하는 횟수를 의미해요.
즉, "1 Epoch를 진행하기 위해 나눈 mini-batch가 몇 개냐"로 생각하시면 됩니다.
예를 들어 볼까요?
총 Data가 1000개 있습니다. Batch Size를 100으로 정했다면 어떻게 될까요?
mini-batch는 "100/1000 = 10"으로 10개겠네요.
1 iteration은 100개의 Data에 대해 학습한 것을 의미합니다.
1 Epoch는 10 iteration으로 진행되겠네요.
이번엔 코드를 보죠
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
import os
# tensorflow Log 출력 제어
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 난수 생성 방식을 고정
np.random.seed(100)
tf.random.set_seed(100)
# data load , drop, split
df = pd.read_csv("data\\data_Advertising.csv")
df.drop(columns=['Unnamed: 0'])
X = df.drop(columns=['Sales'])
Y = df['Sales']
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.3)
# Pandas의 DataFrame을 Tensorflow의 Dataset 형태로 변환
train_ds = tf.data.Dataset.from_tensor_slices((train_X.values, train_Y.values))
# shuffle로 섞어주고 Batch 나누기
train_ds = train_ds.shuffle(len(train_X)).batch(batch_size=5)
# take method로 batch를 꺼내서 feature와 label에 나워서 저장하기
[(train_features_batch, label_batch)] = train_ds.take(1)
print('\nFB, TV, Newspaper batch Data:\n',train_features_batch)
print('Sales batch Data:',label_batch)
pandas를 통해 불러온 Data를 drop, split을 통해 1차 전 처리를 해줬네요.
그리고 Split 한 Data를 "tf.data.Dataset.from_tensor_slices"를 통해 tensor 형태로 변환했습니다.
⚠️주의⚠️
이번 예시의 train_ds는 x, y를 모두 가지고 있습니다.
이와 다르게 x, y를 따로 shuffle 하면 feature와 label의 매칭이 엇갈려서 데이터가 잘못될 수 있으니 주의가 필요합니다!!
모델 구현하기
Keras

Keras는 거의 모든 딥러닝 모델을 간편하게 만들고 훈련시킬 수 있는 딥러닝 프레임워크입니다.
딥러닝 초급자도 쉽게 모델을 개발하고 활용할 수 있도록 직관적인 API를 제공합니다.😀
Tensorflow는 기초 레벨부터 모델을 만듭니다.
굉장한 장점이지만 친절하지 않기 때문에 초보자에게는 단점이죠.
그래서 Keras가 개발되었습니다.
주의할 점은 Keras는 Tensorflow위에서 동작한다는 점입니다. (Tensorflow의 package로 제공됩니다.)

그럼 Keras가 최고인가요? 물론 좋지만 아쉬운 점이 있죠.😥
보다 단순하게 구현할 수 있게 만들어진 만큼 세부적인 조작에서는 Tensorflow가 더 좋습니다.
일반적인 사용방법은 이렇습니다.
tf.keras로 틀을 구현하고, Tensorflow로 모델의 안을 채워 넣죠.
Keras Method로 모델 구현
keras를 이용해 모델을 구현할 때는 크게 2가지만 알면 됩니다.
- 모델 클래스 객체 생성하는 Method
- 모델의 각 Layer를 구성하는 Method
모델 클래스 객체 생성
model = tf.keras.models.Sequential( )위 method를 사용하면 모델의 틀이 생성됩니다.
이제 매개변수로 각 Layer를 구성하는 Method를 넣어주면 되죠.
모델의 Layer 구성하기
# input layer
tf.keras.layers.Dense(units, input_shape=(,), activation=''),
tf.keras.layers.Dense(units, input_dim=, activation=''),
# hidden, ouput layer
tf.keras.layers.Dense(units, activation=''),Keras로 Layer를 구성할 때 Input Layer에서 주의할 점이 있습니다.
바로 "input_shape 혹은 input_dim"인데요.
Input으로 주어질 Data의 shpae이나, dimension을 설정해야 합니다.
Model은 최초의 Input에 대한 정보가 없기 때문에 알려줘야 합니다.
이후 Layer들은 계산에 대한 결과로 Input이 생성되기 때문에 설정하지 않아도 됩니다.
units은 Layer안에 구성할 Neuron(Node)의 수를 의미합니다.
activation은 해당 Layer에 적용한 Activation Function을 설정해줍니다.
(일반적으로 Hidden Layer에는 ReLU, Output Layer에는 이진분류에 sigmoid, 다중분류에 softmax를 써요.)
코드를 보면서 설명할게요.
"객체 생성 + Layer 구성"을 하면 아래와 같습니다.
간단하게 모델이 하나 완성됐네요.
(Layer에 대해 감을 잡기 위해 여러 층을 쌓았지만 이 모델의 성능은 안 좋게 나옵니다.)
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
import os
# tensorflow Log 출력 제어
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 난수 생성 방식을 고정
np.random.seed(100)
tf.random.set_seed(100)
# data load , drop, split
df = pd.read_csv("data\\data_Advertising.csv")
df.drop(columns=['Unnamed: 0'])
X = df.drop(columns=['Sales'])
Y = df['Sales']
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.3)
# Pandas의 DataFrame을 Tensorflow의 Dataset 형태로 변환
train_ds = tf.data.Dataset.from_tensor_slices((train_X.values, train_Y.values))
# shuffle로 섞어주고 Batch 나누기
train_ds = train_ds.shuffle(len(train_X)).batch(batch_size=5)
# take method로 batch를 꺼내서 feature와 label에 나워서 저장하기
[(train_features_batch, label_batch)] = train_ds.take(1)
# Model 구현
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_shape=(4,), activation='sigmoid'),
tf.keras.layers.Dense(10, activation='sigmoid'),
tf.keras.layers.Dense(1, activation='sigmoid'),
tf.keras.layers.Dense(1, activation='sigmoid'),
])
print(model.summary())
모델을 구현하는 하나의 방법이 더 있습니다.
바로 "add" Method를 활용하는 방법이죠. 큰 차이는 없으니 간단히 보겠습니다.
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(10, input_shape=(4,), activation='sigmoid'))
model.add(tf.keras.layers.Dense(10, activation='sigmoid'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
모델 학습하기
모델을 만들었으면 학습을 해야겠죠?
학습에도 2가지 Method를 활용합니다.
- 모델 학습 방식을 설정하는 Method
- 모델을 학습시키기 위한 Method
모델 학습 방식 설정
model.compile(loss, optimizer)위 코드 한 줄이면 간단하게 학습하는 방식을 정의할 수 있습니다.
loss는 Loss Function을 설정하죠.
optimizer는 모델 학습의 Optimization 방식을 정합니다.
(Gradient Descent를 기반으로 한 여러 방식이 있습니다.)
모델 학습
model.fit(train_ds, epochs=, verbose=)train_ds의 자리에 tensor 형식의 Dataset을 입력으로 넣어줍니다.
eopchs는 학습 횟수를 설정하는 부분이겠죠.
verbose는 학습 과정을 출력하는 방식에 대한 옵션입니다. (0: sclient, 1: progress bar, 2: one line per epoch)
이제 구성한 model의 학습을 진행하겠습니다.
(보다 성능이 좋은 model을 위해 Layer구성을 바꿨습니다.)
첫 3번의 Epoch와 비교하면 마지막 3번의 Epoch에서 Loss가 작아진 것을 확인할 수 있네요.
# Model 구현
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_shape=(4,)),
tf.keras.layers.Dense(1),
])
model.compile(loss='mean_squared_error', optimizer='adam')
history = model.fit(train_ds, epochs=100, verbose=1)

모델 평가 및 예측하기
모델 평가 Method
model.evaluate(test_X, test_Y, verbose=0)모델의 평가를 위해서 Split 해둔 test Data set을 활용할 시간입니다.
입력으로 test feature와 label을 주고, verbose 옵션을 설정하면 됩니다.
예측 Method
model.predict(test_X)예측을 위해서는 feature만 입력으로 주면 됩니다
그리고 실제값인 test_Y (label)과 비교하면 되는 거죠!!
마지막 코드입니다.
# Model 구현
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_shape=(4,)),
tf.keras.layers.Dense(1),
])
model.compile(loss='mean_squared_error', optimizer='adam')
history = model.fit(train_ds, epochs=100, verbose=1)
# 평가
loss = model.evaluate(test_X, test_Y)
# 예측
prediction = model.predict(test_X)
# 결과 출력 및 예측값 실제값 비교
print("Test Data의 Loss값: ", loss)
for i in range(5):
print("=======================================")
print("%d Test Data Label: %f" % (i, test_Y.iloc[i]))
print("%d Test Data Prediction: %f" % (i, prediction[i][0]))
예측 결과 첫 Data를 빼고는 아주 근사한 값을 예측하는 데 성공했습니다!!🎉
(실제라면 첫 번째 Data의 오차에 대해 고민해야 하지만 설명을 위한 간단한 data와 model 이므로 넘어가겠습니다.)
여기까지 "딥러닝 모델 구현하기 (Tensorflow, Keras)"에 대해 알아봤어요.
다음에는 "이미지 처리를 위한 딥러닝"에 대해 알아보겠습니다.
글이 도움이 되셨다면 공감 버튼 눌러주세요. 😊
'AI & Data > 이론' 카테고리의 다른 글
| [AI 이론] 딥러닝 - 자연어(Text) 처리 이론과 실습 (Ft.RNN) (0) | 2022.11.17 |
|---|---|
| [AI 이론] 딥러닝 - 이미지 처리 이론과 실습 (Ft. MNIST) (0) | 2022.11.16 |
| [AI 이론] 손실 함수 한방에 끝내기 (Loss Function) (0) | 2022.11.11 |
| [AI 이론] 활성 함수 한방에 끝내기 (Activation Function) (0) | 2022.11.10 |
| [AI 이론] 딥러닝 - 퍼셉트론 한방에 끝내기 (Perceptron) (0) | 2022.11.08 |