
회귀 (Regression)
회귀 분석이란?
둘 이상의 변수가 있을 때 이들 간의 관계를 보여주는 통계적인 방법입니다.
나아가서 데이터를 가장 잘 설명하는 모델을 찾아 입력값에 따른 미래 결과값을 예측하는 알고리즘입니다.
대표적인 예가 TV 프로그램의 시청률 예측입니다.
TV 프로그램의 시청률이, 강수량과 선형적인 관계가 있다고 가정을 해볼게요.
그럼 Data 는 강수량, 시청률 2 가지겠네요.
그리고 최종적으로 강수량에 따른 시청률 예측이 목표입니다.
회귀 분석 알고리즘을 사용해 둘 사이의 상관관계를 파악하고 나아가 미래 결과를 예측하는 모델을 만들어야겠네요.

가정에서 선형의 관계를 갖는다고 했으니 위와 같은 1차 방정식을 세워야 합니다.
이때 적절한 'β0(y절편)'와 'β1(기울기)'을 찾는 것이 중요하겠네요.
그럼 어떤 값이 적절한 값일까요?
바로 실제 데이터들과 찾아낸 방정식 사이의 거리(차이)가 가장 적은 값입니다!
위의 설명을 다시 생각해보면, 완벽한 예측은 불가능에 가깝지만 가장 근사한 결과를 만들어내는 것이 필요합니다.
회귀 알고리즘은 "수치형 데이터"에 적용합니다.
데이터에 대한 설명은 "자료의 형태 (Data)(링크)"에서 다뤘으니 참고하세요.😎
[AI 이론] 자료 형태 (Data)
Data 최근 가장 핫한 기술인 AI는 Data를 기반으로 해요. 수많은 Data를 모으고, AI의 학습에 적합하게 전 처리하는 과정을 거치죠. 즉, AI를 활용하려면 Data를 다룰 줄 알아야한다는 뜻이죠. 그 시작으
kay-dev.tistory.com
단순 선형 회귀 (Simple Linear Regression)
단순 선형 회귀란?
데이터를 잘 설명하는 모델을 직선 형태로 가정한 방법입니다.
바로 위에서 살펴본 예시가 단순 선형 회귀였어요.
말씀드린 것처럼 적절한 'β0(y절편)'와 'β1(기울기)'을 찾는 것이 중요하죠.
그럼 데이터를 잘 설명한다는 것은 어떤 의미일까요?
실제 정답과 내가 예측한 값의 차이가 작을수록 잘 설명한다고 볼 수 있어요.

좀 더 구체적으로 보죠.
아래 그림에서 보면 "실제값 - 예측값" 도 있고, "(실제값 - 예측값)^2" 도 있네요.
앞서 말한 데이터의 "차이"는 단순 "+/-"가 아니라 떨어진 "거리"로 보는 것이 더 맞아요.
즉, 눈여겨봐야 하는 데이터는 "(실제값 - 예측값)^2"라는 말이죠.
이 개념의 손실 함수에서 사용됩니다.

특징
- 가장 기초적이면서 많이 사용되는 알고리즘
- 입력값이 1개인 경우에만 적용 (여러 개라면 다중 선형 회귀 방식이 필요)
- 입력값과 결과값의 관계를 알아보는데 좋음
- 입력값이 결과값에 얼마나 영향을 미치는지 파악
- 두 변수의 관계를 직관적으로 해석할 때 사용
손실 함수 (Loss fuction)
이해하기
손실 함수는 알고리즘이 예측한 값과 실제 데이터의 차이를 비교하는데 쓰는 함수입니다.
손실 함수를 기준으로 모델의 학습이 잘 되고 있는지를 판단할 수 있어요.
단, 학습 중에 사용되는 함수이며 모델의 성능 평가를 위한 지표는 아닙니다!!
단순 선형 회귀는 실제값과 예측값의 차이의 제곱의 합을 손실 함수로 사용해요.
이를 MSE (Mean Squared Error)라고 합니다.
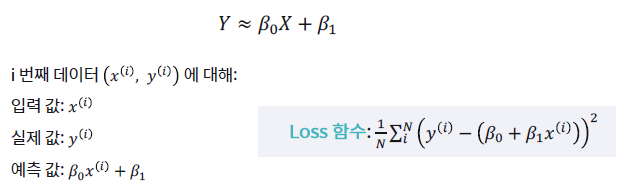
손실 함수 줄이기
여기서 다시 적절한 'β0(y절편)'와 'β1(기울기)'찾기가 등장합니다.
손실 함수의 크기는 'β0(y절편)'와 'β1(기울기)'의 조합으로 조절하기 때문이죠.
드디어 적절한 값을 찾는 방법을 알아볼 시간입니다.

위 사진에서 처럼 여러 방법이 있어요. 그중 경사 하강법에 대해 확인해보죠.
(* "argmin"은 해당 함수값을 최소로 하는 "β0β1"를 반환합니다.)
경사 하강법 (Gradient Descent)
산에서 내려가는 길을 몰라도 한 걸음씩 걸으면서 경사가 가장 가파른 방향으로 내려가면 된다.
경사 하강법은 이런 산을 내려가는 방법에 많이 비유됩니다.

과정은 4단계를 반복하면서 진행합니다.
1️⃣ 'β0(y절편)'와 'β1(기울기)'를 랜덤 초기화합니다.
2️⃣ Loss 값을 계산해줍니다.
3️⃣ Gradiednt를 계산해줍니다. (경사도, 미분)
4️⃣ 'β0(y절편)'와 'β1(기울기)'을 업데이트
여기서 단순 선형 회귀의 과정을 한번 정리하고 넘어갈까요?
데이터의 전처리 (X, y 설정) ➡️ 단순 선형 회귀 모델 학습 ('β0(y절편)'와 'β1(기울기)' 결정)
➡️ 새로운 데이터에 대한 예측
예시
⚠️주의⚠️
Pytorch라는 새로운 라이브러리와 관련 함수, 개념이 등장합니다.
미분을 직접 하지 않고 Loss function과 Gradient를 계산할 수 있고 'β0(y절편)'와 'β1(기울기)'를 update 해줍니다.
유사한 기능을 제공하는 다른 라이브러리들이 더 있으니 참고해주세요.
자세히 설명하면 글이 너무 길어져서 다음에 소개할게요.
이제 'β0(y절편)'는 bias로 'β1(기울기)'는 weight로 표현하겠습니다.
사용한 데이터는 임의로 생성한 값이며 "공백"으로 구분된 100행 2열로 구성되어 있습니다.
이론만 보는 것보다 직접 해보는 게 덜 지루하고 이해도 쉽죠?
가볼까요?
Data 준비
txt 파일의 data를 머신러닝에 활용하기 위해 읽어와 type을 바꿔주는 과정입니다.
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
file = open('data\\regression_data.txt','r')
text = file.readlines()
file.close()
x_data = []
y_data = []
for s in text:
data = s.split() # 공백 기준 split
x_data.append(float(data[0]))
y_data.append(float(data[1]))
x_data = np.asarray(x_data, dtype=np.float32)
y_data = np.asarray(y_data, dtype=np.float32)
Data 확인하기
Data를 확인해야 방향을 정할 수 있겠죠?
matplotlib 라이브러리를 활용했습니다.
plt.figure(1)
plt.plot(x_data, y_data, 'ro') # 'ro' 는 red circle 옵션
plt.xlabel('x-axis')
plt.ylabel('y-axis')
plt.title('Kay data')
plt.show()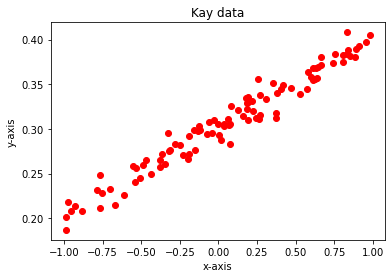
Model 정의
이제 학습시킬 model을 정의합니다.
먼저 학습에 사용된 parameter 들을 정의해주고, model을 Linear 함수로 정의했어요.
다음은 MSE가 보이네요. 그리고 SGD라는 함수도 보이죠. SGD는 Stocastic Gradient Descent입니다.
Gradient Descent는 "전체 Data(Batch)"를 사용해 정확하지만 계산량이 많다는 단점이 있습니다.
이 점을 보완한 게 SGD입니다. SGD는 "일부 Data(mini-batch)"를 사용하는 방식인데요. 정확도는 떨어지지만 계산속도가 훨씬 빠르다는 장점이 있습니다.
# Hyper-parameters define
input_size = 1
output_size = 1
num_epochs =100
learning_rate = 0.1
# Linear regression medel (y = wx + b)
model = nn.Linear(input_size, output_size)
# Loss and optimizer
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
print(x_data.shape, y_data.shape)
if len(x_data.shape) == 1 and len(y_data.shape) == 1:
x_data = np.expand_dims(x_data, axis=-1)
y_data = np.expand_dims(y_data, axis=-1)
print(x_data.shape, y_data.shape)
Model 학습
대망의 학습입니다.
이 과정을 거치면 우리가 생각하는 AI가 탄생하는 거죠.
모델의 학습은 Loss를 줄이는 방향으로 진행합니다. 이때, 학습 횟수를 epoch라고 해요.
Data수가 많지 않고, 간단한 과정이라 쉽고 빠르게 진행이 되네요.
# train model
for epoch in range(num_epochs):
# Convert numpy arrays to torch tensors
inputs = torch.from_numpy(x_data)
targets = torch.from_numpy(y_data)
# Predict outputs with the linear model.
outputs = model(inputs)
loss = criterion(outputs, targets)
# compute gradients and update
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
결과 확인
이제 우리의 AI가 만들어낸 결과를 보는 시간입니다.
강조한 적절한 'bias(y절편)'와 'weight(기울기)'찾기를 성공한 모습이네요.
#print graph
predicted = model(torch.from_numpy(x_data)).detach().numpy()
plt.plot(x_data, y_data, 'ro', label='Origianl data')
plt.plot(x_data, predicted, label='Fitted Line')
plt.legend()
plt.show
다중 선형 회귀 (Multiple Linear Regression)
단순 선형 회귀에서 예를 들었던 "TV 프로그램의 시청률 예측"을 다시 볼게요.
이전에는 TV 프로그램의 시청률이, 강수량과 선형적인 관계가 있다는 가정이었죠.
여기에 요일이라는 새로운 Data도 포함해서 관계를 확인하면 어떨까요?
최종 목표는 그대롭니다. Data에 따른 시청률 예측이죠. 하지만 Data가 강수량, 요일, 시청률 3가지로 늘었어요.
이때 다중 선형 회귀가 사용됩니다.
다중 선형 회귀란?
다중 선형 회귀란 입력값이 2개 이상인 경우에 사용할 수 있는 회귀 알고리즘입니다.

식을 보시면 알겠지만 이번엔 찾아야할 'β'가 참 많네요.
특징
- 여러 개의 입력값과 결과값의 관계를 확인할 수 있어요.
- 어떤 입력값이 결과값에 주는 영향을 확인할 수 있어요.
- 입력값들끼리 서로에 영향을 강하게 줄수록 결과는 신뢰도가 낮아질 확률이 높아요.
손실 함수(Loss Function)
복잡해 보이지만 나오는 개념은 사실 비슷합니다.
다중 선형 회귀의 경우에도 손실 함수를 사용하고 그 정의는 "입력값과 실제값 차이의 제곱의 합"으로 같아요.
단, 찾아야할 'β'가 많아졌으니 식도 길어집니다.

경사 하강법(Gradient Descent)
경사 하강법도 역시 사용합니다.
4단계를 반복하는 것도 동일하죠.
1️⃣ 'β0(y절편)'와 'β1(기울기)'를 랜덤 초기화합니다.
2️⃣ Loss 값을 계산해줍니다.
3️⃣ Gradiednt를 계산해줍니다. (경사도, 미분)
4️⃣ 'β0(y절편)'와 'β1(기울기)'을 업데이트
회귀 평가 지표
회귀 알고리즘의 평가란?
열심히 만든 모델이 얼마나 좋은 모델인지 알아야겠죠? 그리고 성능이 부족하지는 않은지도요.
어떤 것을 기준으로 평가할까요?
목표를 얼마나 잘 달성했는지의 정도를 평가합니다.
실제 값과 모델의 예측 값의 차이에 기반한 평가 방법을 사용하죠. 방법의 예는 아래와 같아요.
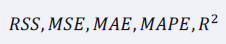
평가 지표
RSS (Residual Sum of Squares)

RSS는 단순 오차입니다.
실제 값과 예측 값의 단순 오차 제곱의 합이죠.
RSS는 그 값이 작을수록 모델의 성능이 좋습니다.
특징
- 가장 간단한 평가방법으로 직관적인 해석이 가능해요.
- 오차를 그대로 이용하기 때문에 입력 값의 크기에 의존적입니다.
- 절대적인 값과 비교는 불가능해요.
MSE (Mean Squared Error)
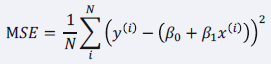
MSE는 평균 제곱의 차입니다. RSS를 Data의 수로 나눈 값입니다.
값이 모델의 작을수록 성능이 높아요.
MSE는 제곱을 이용하기 때문에 이상치에 민감하게 반응합니다.
MAE (Mean Absolute Error)

MAE는 평균 절대값의 오차입니다. 실제 값과 예측 값의 오차의 절대값의 평균이죠.
역시 작을수록 성능이 좋은 모델입니다.
MAE는 변동성이 큰 지표와 낮은 지표를 같이 예측할 경우에 유용해요.
R² (결정 계수)

R² 는 회귀 모델의 설명력을 표현한 지표입니다.
1에 가까울수록 높은 성능의 모델입니다. (작아질수록 안 좋은 성능의 모델입니다.)
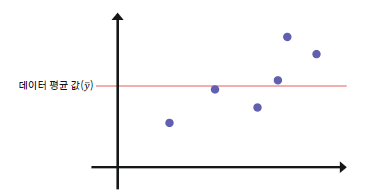
TSS라는 새로운 개념이 보이죠?
TSS는 데이터 평균값과 실제 값의 차이의 제곱입니다.

특징
- 오차가 없을수록 1에 가까운 값이 나와요.
- 값이 0인 경우, 데이터의 평균값을 출력하는 직선 모델을 의미해요.
- 음수 값이 나온 경우는 평균값 예측보다 성능이 좋지 않다는 것을 뜻해요.
참고
Logistic Regression
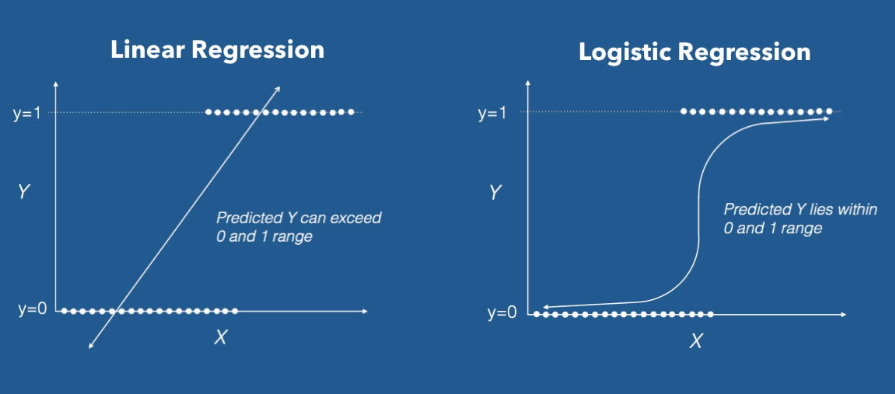
Linear Reagression이 선형적인, 연속적인 값에 대한 알고리즘이죠.
Logistic Regression은 비선형적인 값(0 or 1)에 적용하는 알고리즘입니다.
Linear Regression을 비선형적인 데이터에 적용하면 임의 구강에서 0과 1로 분류할 수 없게 됩니다.
이를 보완하기 위해 Logistic Regression을 사용합니다.
여기까지 "선형 회귀"에 대해 알아봤어요.
다음에는 "분류"를 알아보겠습니다.
글이 도움이 되셨다면 공감 버튼을 눌러주세요. 😊
'AI & Data > 이론' 카테고리의 다른 글
| [AI 이론] 활성 함수 한방에 끝내기 (Activation Function) (0) | 2022.11.10 |
|---|---|
| [AI 이론] 딥러닝 - 퍼셉트론 한방에 끝내기 (Perceptron) (0) | 2022.11.08 |
| [AI Algorithm] 지도학습 - 분류 한방에 끝내기 (Classification / Ft. Decision Tree) (0) | 2022.11.08 |
| [AI 이론] 데이터 전 처리 한방에 끝내기 (Data preprocessing feat.titanic) (0) | 2022.11.03 |
| [AI 이론] 자료 형태 (Data) (0) | 2022.11.02 |