분류 개념
분류란?
분류는 주어진 입력값이 어떤 클래스(Label의 범주)에 속할지에 대한 결과 값을 도출하는 알고리즘입니다.
분류 알고리즘은 다양하게 존재하고, 예측 목표와 데이터 유형에 따라 적용할 알고리즘이 달라집니다.
분류 vs 회귀
앞서 "회귀(Regression) (링크)"에 대해 알아봤죠.
지도 학습 알고리즘 중에서 어떤 경우에 회귀를 쓰고, 언제 분류를 사용할까요?
여러 조건이 있지만, 가장 간단하게 이해할 수 있는 방법이 있습니다.
Data에서 target이 되는 결과 값(Label)의 형태에 따라 구분할 수 있습니다.
"범주형 target은 분류, 수치형 target은 회귀"
[AI Algorithm] 지도학습 - 선형 회귀 한방에 끝내기 (Linear Regression)
회귀 (Regression) 회귀 분석이란? 둘 이상의 변수가 있을 때 이들 간의 관계를 보여주는 통계적인 방법입니다. 나아가서 데이터를 가장 잘 설명하는 모델을 찾아 입력값에 따른 미래 결과값을 예측
kay-dev.tistory.com
분류 알고리즘
분류 문제에는 다양한 알고리즘들이 존재합니다.
몇 가지만 소개할게요.
- 트리 구조 기반: Decision Tree, Random Forest, ...
- 확률 모델 기반: Naive Bayes Classifier, ...
- 결정 경계 기반: Linear Classification, Logistic Regression, SVM, ...
- 신경망: Perceptron, Deep Learning, ...
예시를 통해 이해하기
항공편의 지연 여부를 예측하는 모델을 만들고자 합니다.
이때 feature로는 기상정보(구름양, 풍속)만 사용할 예정입니다.
그렇다면 필요한 데이터는 "과거의 기상정보"와 "당시 항공 지연 여부"입니다.
항공 지연 여부는 "yes or no"로 범주형 Label이겠네요. 즉, 분류 알고리즘을 사용하면 된다는 의미입니다.


왼쪽과 같은 자료가 주어졌습니다.
풍속 4m/s를 기준으로 지연 여부를 나눠볼까요?
오른쪽 자료처럼 깔끔하게 분류가 되겠네요!
굉장히 간단한 예시였지만 분류 알고리즘의 개념을 이해하기에 충분히 도움이 되셨을 거예요.
분류 알고리즘은 "범주형 데이터"에 적용합니다.
데이터에 대한 설명은 "자료의 형태 (Data)(링크)"에서 다뤘으니 참고하세요.😎
의사결정 나무 (Decision Tree)
의사결정 나무란?

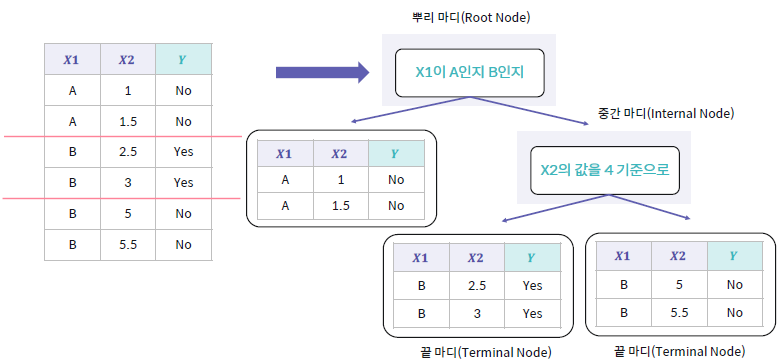
의사결정 나무는 스무고개와 같이 특정 질문들을 통해 정답에 가까워지는 모델입니다.
최상단의 뿌리 마디(Root Node)에서 중간 마디(Internal Node)를 거쳐 마지막 끝마디(Leaf Node, Terminal Node)까지
아래 방향으로 진행하죠.
각 마디(Node)에는 분류 기준이 있고, 진행할 Subtree가 정해집니다.
최종 도달한 끝마디는 Class(Label)를 의미한다고 생각하면 됩니다.
앞서 살펴본 항공 지연 여부 예측모델의 예시에 적용하면 이렇게 되는 거죠!

중간 마디가 필요한 데이터는 어떤지 볼까요?
왼쪽은 feature가 1개, 오른쪽은 2개인 경우입니다.

아이리스 품종 분류
Iris 품종분류 문제는 다중 분류 모델의 대표적인 예시로 유명하죠.
자세한 설명은 "AI의 Toy" 카테고리에서 다루겠습니다.

그래도 Decision Tree가 나왔는데 예시를 건너뛸 순 없겠죠?
"데이터 전처리 한방에 끝내기(링크)"에서 사용한 적이 있는 sklearn 라이브러리를 활용할게요.
[AI 이론] 데이터 전 처리 한방에 끝내기 (Data preprocessing feat.titanic)
머신러닝 이번 글에서는 데이터 전 처리의 관점에서만 머신러닝을 이야기하고 머신러닝의 소개는 다음 기회에 하겠습니다. 머신러닝 과정 이해하기 머신러닝의 전체적인 과정을 정리하면 위
kay-dev.tistory.com
굉장히 친절한 라이브러리라서 많은 것을 할 수 있습니다. 😁
iris 데이터도 저장되어 있고, train set과 test set의 split도 함수로 제공하며, Decision Tree까지 정의되어 있죠.
⚠️ AI에 대해 처음 학습하시는 분들께는 편하지만 독이 될 수도 있으니 주의하세요. ⚠️
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# sklearn에서 제공하는 기본 데이터 load
X, Y = load_iris(return_X_y = True)
# DataFrame으로 변환
df = pd.DataFrame(X, columns=['sepal length', 'sepal width', 'petal length', 'petal width'])
df['class'] = Y
X = df.drop(columns=['class'])
Y = df['class']
# train set, test set을 분류
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.2, random_state=42)
# Decission Tree 모델을 초기화
model = DecisionTreeClassifier()
# 정의한 모델을 학습
model.fit(train_X, train_Y)
# 학습 결과를 시각화
fig = plt.figure(figsize=(25,20))
_ = tree.plot_tree(model,
feature_names=['sepal length', 'sepal width', 'petal length', 'petal width'],
class_names=['setosa', 'versicolor', 'virginica'],
filled=True)
# test set에 대해 예측
pred_X = model.predict(test_X)
print('test_X에 대한 예측 \n{}'.format(pred_X))
'''
test_X에 대한 예측
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]
'''
분류 평가 지표
Confusion Matrix(혼동 행렬)

Confusion Matrix는 분류 모델의 성능을 평가하기 위해 사용합니다.
굉장히 헷갈리죠...😥 하지만 이해하면 쉬워요.
하나만 기억하고 들어가죠. T/F, P/N 은 모델이 예측한 값에 대한 이야기입니다.
- 정답
- TP (True Positive): True(정답)인데 Positive로 예측해서 정답!
- TN (True Negative): True(정답)인데 Negative로 예측해서 정답!
- 오답
- FP (False Positive): False(오답)인데 Positive로 예측해서 오답 (1형 오류)
- FN (False Negative): False(오답)인데 Negative로 예측해서 오답 (2형 오류)
앞으로 소개할 Accuracy, Precision, Recall, FPR은 Confusion Matrix를 기반으로 이해하시면 됩니다.
주요 지표들
지표들을 이해하기 위해 코로나19의 진단키트를 예로 들어볼게요. 🏣
정확도 (Accuracy)

전체 데이터(P+N) 중에서 제대로 분류된 데이터(TP+TN)의 비율을 의미해요.
모델이 얼마나 정확하게 분류하는지를 나타냅니다.
코로나19 진단키트로 이해해볼까요?
10명이 키트를 사용해서 확진자는 확진자로, 비 확진자는 비 확진자로 분류한 사람이 8명이었다고 가정해볼까요?
이 경우는 정확히 분류된 사람이 7명이므로 Accuracy는 80%입니다.
Accuracy는 일반적인 분류 모델의 주요 평가 방법으로 사용합니다.
⚠️ 하지만 정확도에만 집중하면 위험해요. ⚠️
학습 데이터에 과하게 적합된 모델(Overfitting)은 학습 데이터에 대해서는 Accuracy가 굉장히 높지만,
Test 데이터, 새로운 데이터에는 정확도가 굉장히 낮을 수 있어요.
정밀도 (Precision)

모델이 Positive라 분류한 것 중에서 실제값이 Positive인 비율입니다.
코로나19 진단키트 예시를 계속해보죠.
정밀도는 확진자로 분류된 사람들 중 실제 양성일 확률입니다.
진단키트가 확진자로 분류한 사람이 8명인데, 그중 6명만 실제 감염자였다고 생각해볼게요.
이 경우는 6/(2+6)으로 계산해 정밀도가 75%인 모델이군요.
Recall (재현율, TPR - True Positive Rate)

실제 값이 Positive인 것 중에서 모델이 Positive로 분류한 비율입니다.
다시 코로나19 진단키트입니다.
재현율은 실제 양성인 시민을 확진자로 분류할 확률입니다.
진단키트를 사용한 10명 중 실제 확진자는 9명인데 8명을 확진자로 분류했다고 볼게요.
이 경우는 8/(1+8)로 계산해 재현율은 약 88.9%인 모델이네요.
FPR (False Positive Rate)
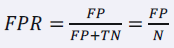
실제 값이 Negative인 것 중에서 모델이 Positive로 잘못 분류한 데이터의 비율입니다.
Recall의 반대 계산이라고 생각하면 편하겠네요.
코로나19 진단키트를 생각해보죠.
FPR은 실제 음성인 시민을 확진자로 분류할 확률입니다.
진단키트를 사용한 10명 중 실제 음성인 사람이 3명이었는데, 그중 1명을 확진자로 분류한 경우죠.
1/(1+2)로 계산해 FPR은 약 33.3%인 모델입니다.
ROC Curve & AUC
ROC Curve는 위에서 살펴본 FPR과 TPR을 시각화한 그래프입니다.
X축은 FPR, Y축은 TPR로 설정한 그래프죠.
AUC(Area Under Curve)는 ROC Curve의 아래 면적을 의미합니다.
모델의 성능을 평가할 때는 AUC를 사용합니다.

분류 평가 지표 정리
분류 평가 지표 6가지를 알아봤습니다.
평가에는 분류의 목적에 따라 다양한 지표를 계산해서 활용해야 합니다.
- 혼돈 행렬: 분류 결과를 전체적으로 보고 싶은 경우
- 정확도: 정답을 얼마나 잘 맞혔는지 보고 싶은 경우
- 정밀도, 재현율: 실제 Positive 데이터에 중요도가 높은 경우
- FPR: 실제 Negative 데이터에 중요도가 높은 경우
- ROC Curve & AUC: FPR, TPR의 변화에 따른 모델의 전체적인 성능을 보고 싶은 경우
유방암 예측하기
유방암 예측은 Iris 품종 예측과 더불어 의사결정 트리에서 유명한 문제입니다.
Iris처럼 sklearn 라이브러리에서 데이터를 제공받을 수 있죠.
이번에는 분류평가지표를 출력하는데 중점을 두겠습니다.
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# sklearn 에서 저장된 유방암 데이터를 load
X, Y = load_breast_cancer(return_X_y = True)
X = np.array(X)
Y = np.array(Y)
print('전체 샘플 수: ', len(X))
print('X의 feature 수: ', len(X[0]))
'''
전체 샘플 수: 569
X의 feature 수: 30
'''
# train set, test set 분류
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.2, random_state=42)
print('train set: ', len(train_Y))
print('클래스 0인 train set: ', len(train_Y)-sum(train_Y))
print('클래스 1인 train set: ', sum(train_Y))
print('test set: ', len(test_Y))
print('클래스 0인 test set: ', len(test_Y)-sum(test_Y)) # sum하면 1만 더해진다. (0은 더해도 0)
print('클래스 1인 test set: ', sum(test_Y)) # 0은 더해도 0
'''
train set: 455
클래스 0인 train set: 169
클래스 1인 train set: 286
test set: 114
클래스 0인 test set: 43
클래스 1인 test set: 71
'''
# Decission Tree 모델을 초기화
model = DecisionTreeClassifier()
model.fit(train_X, train_Y)
y_pred_train = model.predict(train_X)
y_pred_test = model.predict(test_X)
# Confusion Matrix 계산
cm_train = confusion_matrix(train_Y, y_pred_train)
cm_test = confusion_matrix(test_Y, y_pred_test)
print('Train Confusion Matrix: \n {}'.format(cm_train))
print('Test Confusion Matrix: \n {}'.format(cm_test))
'''
Train Confusion Matrix:
[[169 0]
[ 0 286]]
Test Confusion Matrix:
[[40 3]
[ 3 68]]
'''
# Confusion Matrix 를 시각화
fig = plt.figure(figsize=(5,5))
ax = sns.heatmap(cm_train, annot=True)
ax.set(title='Train Confusion Matrix',
ylabel="True Label",
xlabel="Predicted Label")
fig = plt.figure(figsize=(5,5))
ax = sns.heatmap(cm_test, annot=True)
ax.set(title='Test Confusion Matrix',
ylabel="True Label",
xlabel="Predicted Label")
# Accuracy 출력
acc_train = model.score(train_X, train_Y)
acc_test = model.score(test_X, test_Y)
print('train_X Accuracy: %f' % (acc_train))
print('test_X Accuracy: %f' % (acc_test))
'''
train_X Accuracy: 1.000000
test_X Accuracy: 0.947368
'''
# Precision 출력
precision_train = precision_score(train_Y, y_pred_train)
precision_test = precision_score(test_Y, y_pred_test)
print('train_X Precision: %f' % (precision_train))
print('test_X Percision: %f' % (precision_test))
'''
train_X Precision: 1.000000
test_X Percision: 0.957746
'''
# Recall 출력
recall_train = recall_score(train_Y, y_pred_train)
recall_test = recall_score(test_Y, y_pred_test)
print('train_X Recall: %f' % (recall_train))
print('test_X Recall: %f' % (recall_test))
'''
train_X Recall: 1.000000
test_X Recall: 0.957746
'''

여기까지 "분류"에 대해 알아봤어요.
다음에는 "퍼셉트론"에 대해 알아보겠습니다.
글이 도움이 되셨다면 공감 버튼 눌러주세요. 😊
'AI & Data > 이론' 카테고리의 다른 글
| [AI 이론] 활성 함수 한방에 끝내기 (Activation Function) (0) | 2022.11.10 |
|---|---|
| [AI 이론] 딥러닝 - 퍼셉트론 한방에 끝내기 (Perceptron) (0) | 2022.11.08 |
| [AI Algorithm] 지도학습 - 선형 회귀 한방에 끝내기 (Linear Regression) (0) | 2022.11.03 |
| [AI 이론] 데이터 전 처리 한방에 끝내기 (Data preprocessing feat.titanic) (0) | 2022.11.03 |
| [AI 이론] 자료 형태 (Data) (0) | 2022.11.02 |