오늘은 "의료기관"데이터 분석을 해볼게요. 최종 목표는 "서울의 종합병원 위치를 지도에 표시" 것입니다. 정확히 말하면 AI를 다루기 전 단계인 "데이터 분석"입니다.
데이터 찾기
먼저 분석할 데이터가 있어야겠죠? 데이터는공공데이터포털(링크)에서 제공하는 공공데이터를 활용하겠습니다.
방법은 간단해요.
공공데이터 포털 접속 ➡️ 원하는 데이터 검색 ➡️ 다운로드하기
데이터는 csv 파일이나 xml, 오픈 API 등으로 제공됩니다. 오늘 활용할 데이터는 소상공인 시장 진흥공단에서 제공하는 "의료기관" 데이터입니다. csv 파일이네요. 최근 수정일은 21년 8월 26일이네요.
서울시 종합병원 위치 분석
데이터 확인
어떤 데이터인지 파악을 해야 전 처리를 할 수 있겠죠? 확인부터 해봅시다!
데이터 불러오기
몇 가지 준비와 함께 데이터를 확인해볼게요. 분석에 필요한 파이썬 라이브러리와 데이터를 불러오는 것으로 시작합니다.
⚠️주의할 점⚠️은 한글입니다. OS 환경에 맞는 폰트를 설정하고, Data Load 시 encoding 옵션도 신경 써주세요.
import numpy as np # 수치계산
import pandas as pd # data 분석의 기본
import seaborn as sns # 시각화
import matplotlib.pyplot as plt # 시각화
# Windows OS 한글 폰트 설정
plt.rc('font', family='Malgun Gothic')
# Data Load
df = pd.read_csv("data\\의료기관.csv", low_memory=False, encoding='cp949')
df.shape
'''
(91335, 39)
'''
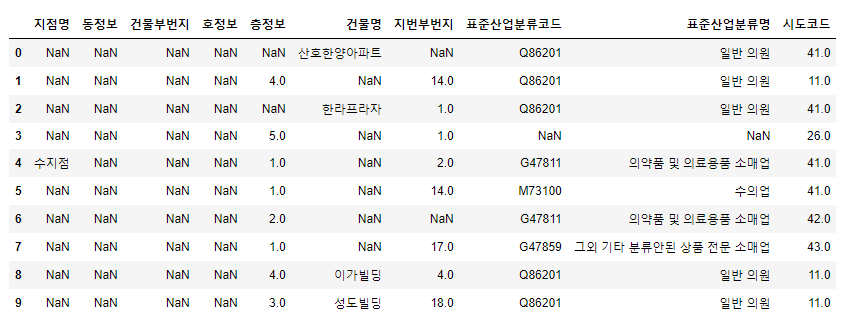
요약은 간단하게 했으니, 실제 데이터를 확인해볼까요? (*head와 tail 함수의 매개변수로 입력한 정수들은 출력할 row의 수를 의미합니다. default로 5개를 출력합니다.)
df.head(1) # 첫 번째 row의 데이터를 출력
df.tail(1) # 마지막 row의 데이터를 출력
df.sample() # 샘플로 미리보기 출력
분석 시작
결측치
데이터를 요약한 내용 중에 결측치가 있는 걸 확인했죠? 자세히 보겠습니다.
df.isnull() # 각 Data가 결측치인지 T/F 출력
df.isnull().sum() # column별 결측치의 수 출력
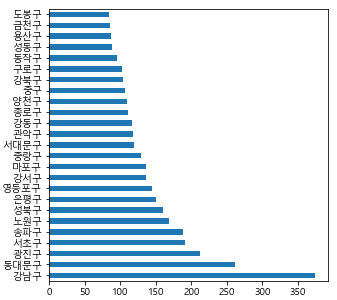
df.isnull().sum().plot.barh(figsize=(10,7)) # 결측치를 bar chart로 출력
# barh는 bar chart의 x,y 축을 바꾼 chart
# figsize를 조절해 column 명들이 겹치지 않게 위치
흠... 하나씩 조회하려니 너무 번거롭네요. 🤔 당연히 다른 방법이 있죠!! .describe()를 사용하면 개수, 평균, 표준편차, 최소, 25%, 50%, 75%, 최대값을 한 번에 볼 수 있어요. 물론 여러 column들을 한번에 조회할 수도 있습니다. (단, 리스트 형태로 조회해야합니다.)
df["위도"].describe()
df[["위도", "경도"]].describe()
⚠️참고⚠️ 문자열 데이터도 decribe를 통해 요약할 수 있어요. 숫자 데이터와 다르게 최대, 최소 등의 통계치는 없는 것을 볼 수 있습니다.
df.describe(include="object")
unique는 중복을 제거한 data의 수를 보여줍니다. ('1'이면 모두 중복이라는 뜻이죠.) top은 가장 많이 등장하는 data를 보여줍니다. freq는 top으로 등장하는 data의 빈도수를 보여줍니다.
unique 값을 사용해 중복을 제거한 data를 직접 조회할 수도 있어요.
df["상권업종대분류명"].unique() # 중복을 제거하고 남은 data
df["상권업종대분류명"].nunique() # 중복을 제거하고 남은 data 수
df["상권업종중분류명"].unique() # 중복을 제거하고 남은 data
df["상권업종중분류명"].nunique() # 중복을 제거하고 남은 data 수
df["상권업종소분류명"].unique() # 중복을 제거하고 남은 data
df["상권업종소분류명"].nunique() # 중복을 제거하고 남은 data 수
그룹화된 통계 값
이번엔 Column에 대한 통계를 확인하겠습니다.
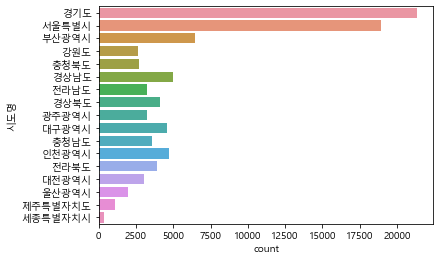
city_count = df["시도명"].value_counts() # "시도명"의 data 통계화
city_countN = df["시도명"].value_counts(normalize=True) # "시도명"의 data 비율 통계화
위 통계를 시각화해볼까요? bar chart와 pie chart 2가지를 볼 건데요. 사실 pie chart는 오해의 소지가 있어 일반적으로는 권장하지 않는다고 해요.
city_count.plot.barh(grid=True) # bar chart
city_count.plot.pie(figsize=(7,7)) # pie chart
시각화를 다른 방법으로도 할 수 있습니다. 처음에 "seaborn" 라이브러리를 불러온 것 기억하시나요? 써봐야죠!
sns.countplot(data=df, y="시도명")
코드를 보면 앞선 방법과 다른 점이 보입니다. pandas를 활용한 시각화는 data에서 통계치를 구하고, 구한 값을 이용해 시각화를 해야 했어요. 하지만 seaborn은 보다 편합니다. 입력으로 DataFrame 전체를 설정하고, x나 y축에 표현할 column명을 입력하면 통계 값을 알아서 계산하고 차트까지 출력할 수 있어요. 물론 한 번에 처리해주는 만큼 데이터양에 따라 속도가 느려진다는 점은 단점입니다.
데이터 분류하기
특정 데이터만 조회해서 볼 수 있는 방법을 살펴볼게요. 예를 들면 "상권업종중분류명"이라는 column에서 "약국/한약방"이라는 값을 갖고 있는 data를 모두 조회하는 거죠. copy() 함수를 사용하면 "df_medical"을 변형해도 원본 data에 영향을 주지 않습니다.
code를 단계적으로 작성했어요. 첫 code에 대한 결과를 보면 "행에 대한 특정 조건"으로 조회해서 해당하는 "모든 행(열은 29개인 상태)"이 결과로 나왔죠. 이 상태에서 "열에 대한 조건"을 주어 최종적인 결과가 나왔습니다. 마지막 code에서 사용한 .value_counts()를 사용하면 data별 개수를 파악할 수도 있습니다.
약국을 확인해볼까요? 이번엔 여러 조건으로 data를 분류하고 차트까지 확인해볼게요. 방식은 유사합니다. 단, 조건문에서"and"가 아닌 "&"를 사용하고 있어요. (pandas의 특징입니다.)
왼쪽 data는 서울지도와 비슷한 느낌이네요. 긴 작업 끝에 왼쪽 data에서 오른쪽의 data를 추출했어요. 뭔가 뿌듯하죠?😎
최종 결과 확인
이제 최종 목표인 "서울의 종합병원 위치를 지도에 표시"하기에 딱 한 단계만 남았어요.
Folium
마지막 단계에 앞서 새로운 라이브러리를 간단하게 소개할게요. 바로 Folium인데요, 맨 처음에 import 하지 않고 숨겨둔 녀석입니다. 😛
Folium은 leaftlet.js를 기반으로 지도를 그려주는 Python 라이브러리입니다. 다른 시각화 패키지에 비해 오래되었고, 안정적이라고 하네요. 또한 OpenStreetMap, Mapbox, Stamen 등 여러 내장 지도 이미지들을 제공한다고 해요. 자세한 소개는 python 카테고리에서 하도록 할게요.
설치하기
Anaconda 환경에서 folium 설치는 간단합니다. 관리자로 Anaconda promt를 실행하고 아래 코드를 입력해주세요.
지금까지 전 처리한 data를 "geo_df"에 copy 하고 시작했어요. 중간에 통계치에서 다룬 .mean() 함수가 보이죠. 지도의 default 위치를 이용하는 데 사용했네요. 그리고 for 문을 통해서 지도에 표시할 popup 내용과 marker를 설정해주면 끝입니다.
결과는... 성공🎉
여기까지 "서울시 종합병원 위치 분석"을 해봤어요. 과정이 확실히 길고 복잡해 보이지만 천천히 따라 하면 누구든 할 수 있어요! 글이 도움이 되셨다면 공감 버튼 눌러주세요.😊