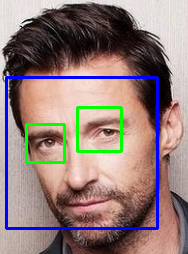
물체 검출 알고리즘
오늘은 영상 관련 Toy project를 하기 위해
물체의 특징 기반 검출 알고리즘인 Haar cascade에 대해 알아보겠습니다.
(얼굴 검출에 흔하게 소개되는 이론입니다.)
Haar cascade algorithm
Haar feature는 "Alfred Haar"에 의해 1909년에 제안되었다고 해요.
오늘날의 Convolution Kernel과 하는 일은 유사합니다.
2001년 Viola와 Jones가 "Rapid Object Detection using a Boosted Cascade of Simple Features"라는 논문에서
특징 기반의 물체 검출 Algorithm으로 "Haar cascade"를 소개했습니다.
Algorithm은 크게 4가지 단계로 구성됩니다.
- Haar feature selection
- Creating integral images
- AdaBoost training
- Cascadeing classifiers
Haar feature selection
첫 단계입니다. 이미지에서 Haar feature를 계산하는 단계죠.

위에 있는 그림은 특징 추출에 사용되는 Feature들입니다.
이미지에서 가장 특출난 특징을 찾는 친구들이죠.
이 친구들이 이미지를 스캔하면서 인접한 Feature 내의 Pixel값의 합끼리 비교하는 방식을 이용합니다.

여기서 말한 "특징"은 위 사진과 같은 사각형들을 물체에 대해 Convolution 해서 수치로 나타내 판별합니다.
구체적으로 알아볼게요.

Edge detection가 가장 기본적이니까 대표로 볼게요.
(Edge detection 만해도 Algorithm이 많지만 원리에 대해서만 이해해 볼게요.)
영상에서 Edge란 영상의 밝기가 낮은 값에서 높은 값으로(반대도 포함) 변하는 지점에 존재하는 부분을 의미합니다.
Edge는 객체의 경계를 나타내고, 모양, 방향성을 탐지할 수 있는 등의 정보를 가지고 있다는 뜻이죠.
보시는 것처럼 2개의 영역을 가지 feature를 사용합니다.
검은 영역끼리, 흰 영역끼리 Pixel 값들을 더해줍니다.
이 때, 값을 비교해서 큰 값이 나오는 곳이 이미지의 밝은 곳입니다. (일반적인 Pixel 값의 특징)
그리고 이 Pixel값들의 차이를 계산해줍니다.
우리가 미리 설정한 값을 넘는 곳을 Edge라고 판단해 저장해 주면 이번 과정은 끝납니다.
(Edge가 없는 영역이라면 "0"에 가까운 수치가 나오겠죠?)

이렇게 이미지 데이터의 밝기 차이를 이용해서 물체의 형태를 얻어냅니다.
Feature들을 작게 하면 보다 세세하게 분석할 수 있지만, 연산량이 그만큼 어마어마하게 커집니다.
하지만 연산량을 줄이고도 충분히 물체를 인식할 수 있습니다.
그 예가 바로 "사람 얼굴 인식"이죠.
사람 얼굴에 공통적으로 나타나는 특징이 있기 때문이죠.
"Stage 0"처럼 큰 크기의 Haar featur를 이용해서 쉽게 얼굴인지 아닌지를 판단할 수 있습니다.
물론 Haar feature algorithm에도 단점은 있습니다.
- 이미지의 밝기 차이를 이용한다.
- 밝기 차가 심하게 크거나 거의 없는 부분은 검출이 힘듭니다.
- 모든 특징을 추출하려면 연산량이 많다.
- 모든 특징을 추출하려면 여러 크기의 feature들을 이용해야 하고 그 feature들이 이미지 전체를 돌아야 합니다.
Creating integral images
Haar feature를 계산하는 과정의 연산량이 많다는 단점을 해결하기 위해
Haar 계산에 "Integral image"를 사용합니다.
큰 이미지라도 빠르게 지정한 영역의 Pixel 값의 합을 구할 수 있죠.
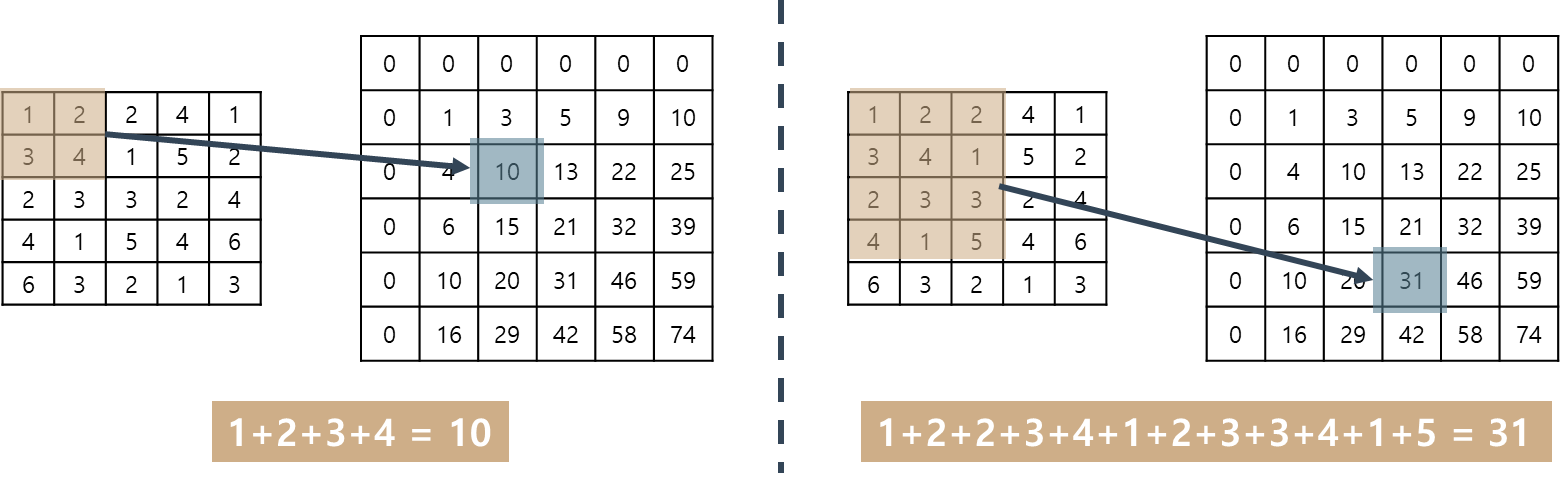
위 그림을 보면서 설명할게요. 2가지 예가 있으니 이해하는데 도움되실 거예요.
왼쪽이 "원래 이미지", 오른쪽이 "Integral image"입니다.
Integral image에서 "0"으로 채워진 맨 왼쪽과 위쪽 줄을 무시하면 원래 이미지와 같은 크기가 남는군요.
그 상태에서 보면 Integral image는 원래 이미지에 대응하는 영역의 모든 값을 더한 값이 입력되어 있네요.
이해가 되시나요?
좌표로 생각해서 다시 볼게요. (추가된 "0"들은 무시하고 보는 겁니다.)
왼쪽 예에서 Integral image의 (2,2)의 "10"은 원래 이미지의 (0,0) ~ (2,2)의 모든 값을 더한 값입니다.
오른쪽 예도 똑같아요.
Integral image의 (4,3)의 "31"은 원래 이미지의 (0,0) ~ (4,3)까지의 모든 값을 더한 값이네요.

이해가 됐으니 이제 가 어떻게 연산량을 줄여주는지 알아보죠.
Integral image의 맨 왼쪽과 위쪽에 추가한 "0"들이 이제 사용됩니다. 다 필요가 있었던 거죠.
기존 이미지의 일부 영역을 지정하고 그 내부 값을 구해볼게요.
Integral image에서 대응하는 좌표(46)를 기준으로 정합니다.
그리고 기준 좌표의 왼쪽과 위쪽 값은 빼주고, 대각선 값은 더해주면 됩니다.
이렇게 Integral image를 이용하면 연산량이 줄어든다는 것을 눈으로 확인할 수 있네요.
AdaBoost training
먼저 Boosting 이 뭔지 알아볼까요?
Boosting은 단순 규칙들의 단계적인 학습을 통해 정확한 결과를 도출하는 것을 의미해요.
Boosting을 이용해 특정한 객체를 찾는 과정은 통계적인 모형을 근거로 합니다.
먼저 찾고자 하는 객체가 포함된 샘플과 포함되지 않은 샘플을 입력으로 학습해요.
학습하는 동안 샘플로부터 여러 특징점들이 추출되고, 객체를 분류할 수 있는 고유 특징이 선택됩니다.
이러한 특징 정보들은 통계적 모델의 입력으로 저장되죠.
AdaBoosting은 Adaptive Boosting의 합성어인데요.
약한 분류기(Weak classifier)들이 상호 보완하도록 순차적(Sequential)으로 학습하고, 이들을 조합해
강한 분류기(Strong calssifier)의 성능을 향상시키는 Algorithm입니다.
(Boosting을 할 때 비정상 데이터에 빠르게 적응해 예측력을 높인다고 해서 Adaptive가 붙었어요.)
AdaBoosting은 단순하고 효율적인 방법이라 가장 대중적이죠.
하지만 AdaBoosting을 이용해 얼굴을 감지하려면 사람의 얼굴에서 수많은 특징점을 추출해야 하는 문제가 있었습니다.
이를 해결하기 위해 위에서 알아본 "Haar feature selection"이 사용됩니다.
오늘의 주제인 Haar cascade의 얼굴 인식 과정에서는 어떻게 사용되는지 알아보죠.

앞서 Haar feature selection을 통해 구한 "특징"들의 대부분은 의미가 없습니다.
예를 들면 위 그림의 두 가지 Haar feature는 눈 주위에서만 의미가 있는 "특징"인 거죠.
이 중 도움이 되는 특징을 골라야 하고, 그 처리 성능을 향상시키는데 AdaBoost를 사용합니다.
AdaBoosting의 과정은 가중치를 부여하면서 학습합니다.
약한 분류기들이 순차적으로 학습을 진행하고, 그 에러율을 계산해 가중치를 부여하죠.
에러율이 높을수록 가중치를 크게 부여해 잘못 분류한 Data에 대해 더 집중적으로 학습합니다.
이렇게 가중치가 부여된 약한 분류기들을 조합해서 강한 분류기를 만들어냅니다.
Cascade classifier
AdaBoosting을 지나고 남은 "특징"을 적용해서 얼굴을 검출할 차례입니다.
물론 그대로 적용하면 계산량이 너무 많아 비효율적이겠죠.
이미지의 대부분은 얼굴이 없는 영역일 겁니다.
그래서 Filter가 있는 영역이 얼굴인지 아닌지를 개별로 체크하는 방법을 사용하죠.
낮은 단계에서는 빠르게, 상위 단계에서는 조금 더 오래 걸리는 연산을 합니다.
여기서 Filter가 이미지 위를 이동할 때 "특징"을 모두 적용하지 않고
여러 단계의 그룹을 묶어서 사용하는 방식을 Cascade classifier라 합니다.
첫 단계에서 얼굴이 아니라고 판단하면 다음 위치로 Filter를 이동합니다.
첫 단계에서 얼굴이라고 판단했다면 위치를 이동하지 않고 바로 다음 단계의 "특징"을 적용하는 방식이죠.
Haar cascade (Ft. OpenCV)
지금까지 얼굴을 인식하는 Algorithm 4단계에 대해 알아봤습니다.
그런데 얼굴을 인식하고자 하면 매번 저 과정을 통해 "Machine learning Model"을 만들어야 할까요?
물론 아닙니다!
"OpenCV"는 원하는 물체를 검출하기 위해 필요한 학습 방법을 제공합니다.
얼굴과 눈을 검출하는 분류기를 미리 학습시켜서 XML 포맷을 제공하고 있죠.
XML 파일을 다운로드하시려면 아래 링크를 확인해보세요!
(⚠️ 참고로 OpenCV는 실시간 컴퓨터 비전을 목적으로 한 프로그래밍 라이브러리입니다.)
GitHub - opencv/opencv: Open Source Computer Vision Library
Open Source Computer Vision Library. Contribute to opencv/opencv development by creating an account on GitHub.
github.com
이제 직접 해볼까요?
import numpy as np
import cv2 as cv
'''
OpenCV에서 제공한 XML 포맷의 분류기 로드
- frontalface: 정면 얼굴
- eye: 눈
'''
face_cascade = cv.CascadeClassifier('data\\haarcascades\\haarcascade_frontalface_default.xml')
eye_cascade = cv.CascadeClassifier('data\\haarcascades\\haarcascade_eye.xml')
'''
얼굴과 눈을 검출할 test image를 불러와서 Gray scale로 변경
'''
img = cv.imread('data\\test.jpg')
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
'''
test image에서 얼굴 검출
'''
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
'''
얼굴 검출 후 얼굴에 대한 좌표를 받음
'''
for (x,y,w,h) in faces:
'''
얼굴의 위치를 rectangle로 표시
'''
cv.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
'''
ROI: Region of interest (관심영역 설정)
눈 검출을 위해 얼굴 영역을 ROI로 설정
'''
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
'''
test image에서 눈 검출
'''
eyes = eye_cascade.detectMultiScale(roi_gray)
'''
눈의 위체 좌표를 받음
'''
for (ex,ey,ew,eh) in eyes:
'''
원본 image에 눈의 위치 표시
'''
cv.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
'''
결과 출력
'''
cv.imshow('img',img)
cv.waitKey(0)
cv.destroyAllWindows()
몇 가지 새로운 부분이 보이시나요?
앞서 소개한 대로 Opencv 라이브러리를 사용했습니다.
그리고 XML 포맷의 파일들을 로드했는데요.
얼굴과 눈을 검출하는 데 사용할 예정입니다.
먼저 ROI(Region of interest)라는 개념입니다.
영상 처리에서 사용하는 용어인데요, 말 그대로 관심 있는 영역이라고 생각하시면 됩니다.
지금의 경우 눈을 검출하기 위해 얼굴을 ROI로 설정했죠.
혹시 얼굴이 아닌 부분에서 눈과 같은 특징이 나오더라도 관심이 없다는 뜻입니다.
이렇게 보면 참 편합니다
어느 영역에서 검출할지만 정해서 OpenCV에서 제공하는 함수에 넣으면 되니까요.
하지만... 기본 제공하는 것인 만큼 성능이 뛰어나지는 않습니다. 😨
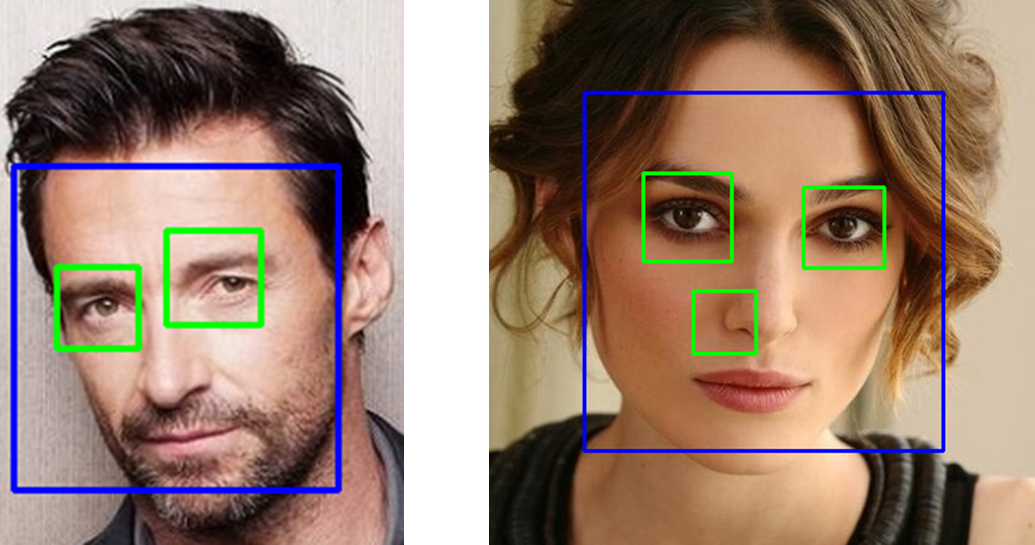
왼쪽은 잘 인식된 경우지만
오른쪽을 보시면 코 쪽에도 얼굴이 있는 것처럼 인식하고 있네요.😁
앞으로 "Haar cascade"을 응용해서 Toy project를 진행할 계획입니다.
(물론 Haar cascade가 아닌 다른 Algorithm을 사용할 수도 있습니다)
여기까지 "Haar Cascase와 얼굴 인식"에 대해 알아봤어요.
글이 도움이 되셨다면 공감 버튼 눌러주세요. 😊
'AI & Data > Toy & Library' 카테고리의 다른 글
| [AI Toy] 서울의 종합병원 위치 분석하기 (Ft. 공공데이터 포털) (0) | 2022.11.04 |
|---|---|
| [Python] Matplotlib 라이브러리 (Line, Bar, Histogram) (0) | 2022.10.27 |
| [Python] Pandas 라이브러리 (Series 와 DataFrame) (0) | 2022.10.27 |
| [Python] Numpy 라이브러리 (feat. indexing, slicing) (0) | 2022.10.26 |